

L'histoire d'internet selon Ars Technica
-
Dans notre nouvelle série en 3 parties, nous nous souvenons des personnes et des idées qui ont fait Internet.

En un sens très réel, Internet, ce merveilleux réseau mondial de communication numérique que vous utilisez actuellement, a été créé parce qu’un homme était agacé d’avoir trop de terminaux informatiques dans son bureau.
C’était en 1966. Robert Taylor était directeur du Bureau des techniques de traitement de l’information de l’Agence des projets de recherche avancée. L’agence avait été créée en 1958 par le président Eisenhower en réponse au lancement de Spoutnik . Taylor travaillait donc au Pentagone, un lieu idéal pour des acronymes comme ARPA et IPTO. Il disposait de trois terminaux massifs entassés dans une pièce adjacente à son bureau. Chacun était connecté à un ordinateur central différent. Leur fonctionnement était légèrement différent, et il était frustrant de devoir se souvenir de multiples procédures pour se connecter et récupérer des informations.

Recréation par l’auteur du bureau de Bob Taylor avec trois télétypes (une simple copie de la frappe clavier d’une machine à une autre)À cette époque, les ordinateurs occupaient des pièces entières et les utilisateurs y accédaient via des terminaux téléscripteurs – des machines à écrire électriques reliées soit à un câble série, soit à un modem et à une ligne téléphonique. L’ARPA finançait de nombreux projets de recherche aux États-Unis, mais les utilisateurs de ces différents systèmes n’avaient aucun moyen de partager leurs ressources. Ne serait-ce pas formidable qu’un réseau relie tous ces ordinateurs ?
Le rêve prend forme
Le prédécesseur de Taylor, Joseph « JCR » Licklider, avait publié en 1963 une note décrivant de manière fantaisiste un « réseau informatique intergalactique » permettant aux utilisateurs de différents ordinateurs de collaborer et de partager des informations. L’idée était avant tout ambitieuse, et Licklider ne parvint pas à la concrétiser. Mais Taylor savait qu’il en était capable.
Dans une interview en 1998 , Taylor expliquait : « La plupart des financements publics sont régis par des comités qui décident de qui reçoit quoi et de qui fait quoi. Avec l’ARPA, ce n’était pas le cas. La personne responsable du bureau concerné par cette technologie particulière – dans mon cas, l’informatique – était celle qui décidait des financements, des actions à entreprendre et des interdictions à prendre. La décision de lancer l’ARPANET m’appartenait, avec très peu, voire aucune formalité administrative. »
Taylor s’est rendu dans le bureau de son supérieur, Charles Herzfeld. Il a expliqué comment un réseau pourrait faire gagner du temps et de l’argent à l’ARPA en permettant à différentes institutions de partager leurs ressources. Il a suggéré de commencer par un petit réseau de quatre ordinateurs comme preuve de concept.
« Est-ce que ça va être difficile à faire ? » a demandé Herzfeld.
« Oh non. On sait déjà comment faire », répondit Taylor.
« Excellente idée », a dit Herzfeld. « Lance-toi. Tu as un million de dollars de plus dans ton budget. Vas-y. »
Taylor ne mentait pas, du moins pas complètement. À l’époque, de nombreuses personnes à travers le monde s’intéressaient aux réseaux informatiques. Paul Baran, travaillant pour la RAND, publia en 1964 un article décrivant comment un système de réseau militaire distribué pourrait être rendu résilient même si certains nœuds étaient détruits lors d’une attaque nucléaire. Au Royaume-Uni, Donald Davies proposa indépendamment un concept similaire (sans les armes nucléaires) et inventa un terme pour désigner le mode de communication de ces types de réseaux : « commutation de paquets ».
Sur un réseau téléphonique classique, après quelques commutations de circuits, l’appelant et le répondeur étaient connectés via un fil dédié. Ils en avaient l’usage exclusif jusqu’à la fin de l’appel. Les ordinateurs communiquaient par courtes rafales et ne nécessitaient pas de pauses comme les humains. Il serait donc inutile que deux ordinateurs monopolisent une ligne entière pendant de longues périodes. Mais comment plusieurs ordinateurs pourraient-ils communiquer simultanément sans que leurs messages ne soient mélangés ?
La commutation par paquets était la solution. Les messages étaient divisés en plusieurs fragments. L’ordre et la destination étaient indiqués pour chaque paquet. Le réseau pouvait ensuite acheminer les paquets de la manière la plus logique. À destination, tous les paquets appropriés étaient placés dans le bon ordre et réassemblés. C’était comme déménager une maison à travers le pays : il était plus efficace d’acheminer toutes les pièces dans des camions séparés, chacun empruntant son propre itinéraire pour éviter les embouteillages.
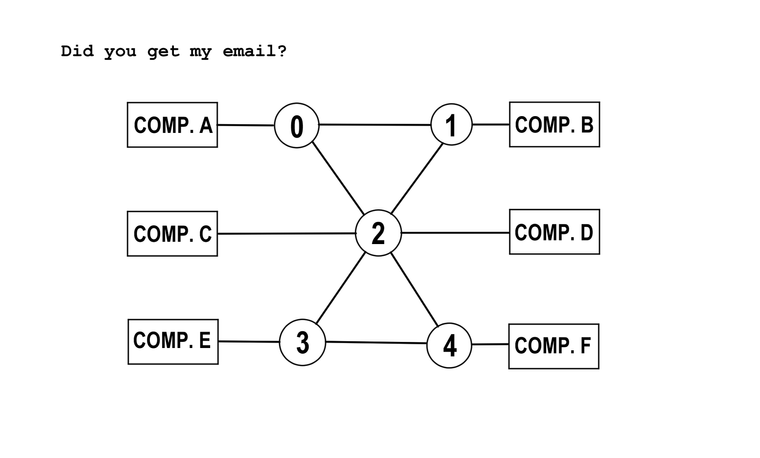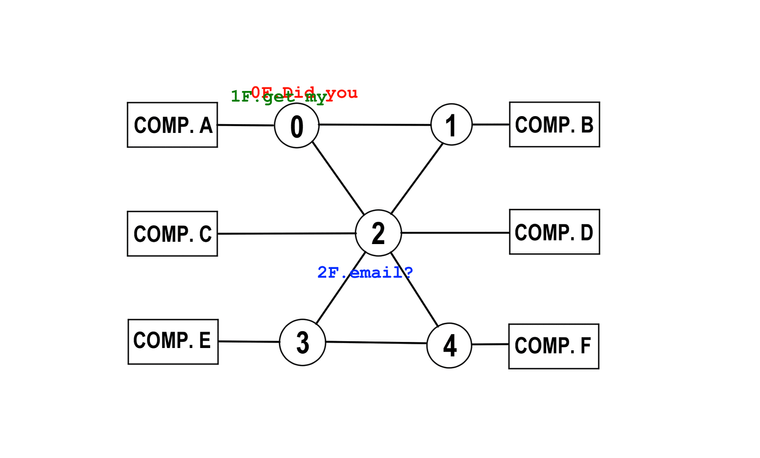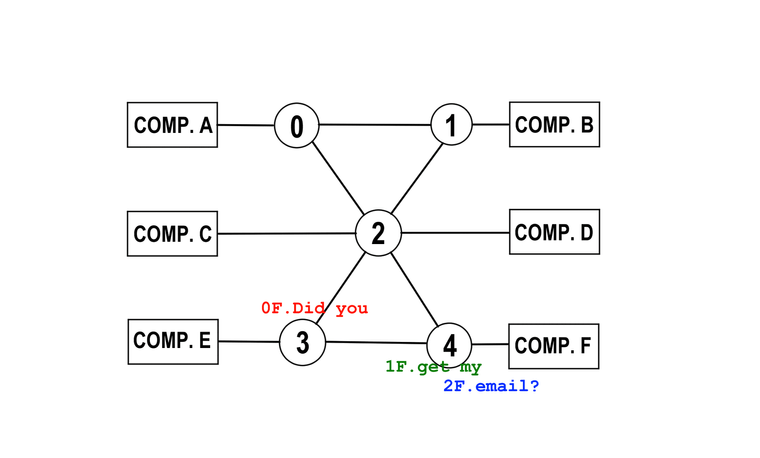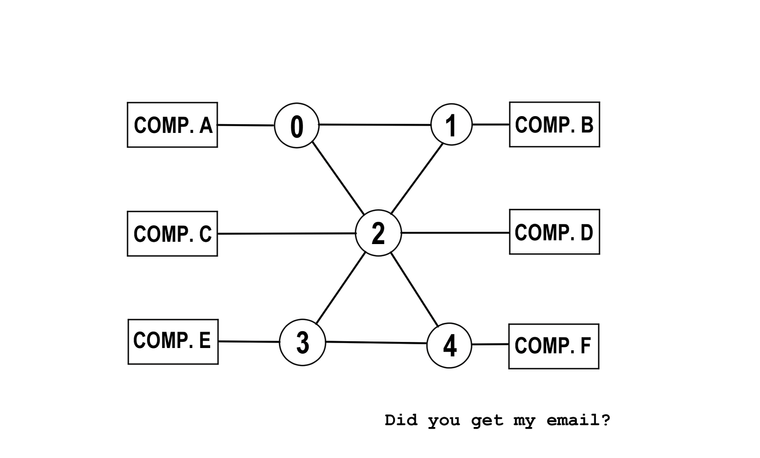
Fin 1966, Taylor avait embauché un directeur de programme, Larry Roberts. Roberts esquissa le schéma d’un réseau potentiel sur une serviette en papier et rencontra son équipe pour proposer une conception. L’un des problèmes résidait dans le fait que chaque ordinateur du réseau devrait utiliser une grande partie de ses ressources pour gérer les paquets. Lors d’une réunion, Wes Clark transmit une note à Roberts disant : « Vous maîtrisez le réseau de fond en comble. » L’autre solution de Clark consistait à envoyer plusieurs ordinateurs plus petits pour se connecter à chaque hôte. Ces machines dédiées se chargeraient de la création, du transfert et du réassemblage des paquets.
Une fois la conception terminée, Roberts a lancé un appel d’offres pour la construction de l’ARPANET. Il ne restait plus qu’à choisir l’offre gagnante et le projet pouvait commencer.
BB&N et les IMP
IBM, Control Data Corporation et AT&T furent parmi les premiers à répondre à la demande. Ils la rejetèrent tous. Leurs raisons étaient les mêmes : aucun de ces géants ne croyait que le réseau était réalisable. IBM et CDC estimaient que les ordinateurs dédiés seraient trop coûteux, mais AT&T affirma catégoriquement que la commutation par paquets ne fonctionnerait pas sur son réseau téléphonique.
Fin 1968, l’ARPA annonça le lauréat de l’appel d’offres : Bolt Beranek et Newman. Le choix semblait étrange. BB&N avait débuté comme cabinet de conseil spécialisé dans les calculs acoustiques pour les théâtres. Mais la nécessité de ces calculs conduisit à la création d’une division informatique, dont le premier responsable n’était autre que JCR Licklider. En réalité, certains employés de BB&N travaillaient déjà sur un projet de construction de réseau avant même l’envoi de l’appel d’offres de l’ARPA. Robert Kahn dirigea l’équipe qui rédigea la proposition de BB&N.
Leur projet consistait à créer un réseau de « processeurs de messages d’interface », ou IMP, à partir d’ordinateurs Honeywell 516. Il s’agissait de versions renforcées du DDP-516 mini-ordinateur 16 bits . Chacun disposait de 24 kilo-octets de mémoire centrale et ne disposait d’aucun autre stockage de masse qu’un lecteur de bande papier. Chaque ordinateur coûtait 80 000 dollars (environ 700 000 dollars aujourd’hui). À titre de comparaison, un mainframe IBM 360 coûtait entre 7 et 12 millions de dollars à l’époque.

Un IMP original, le premier routeur au monde. Il avait la taille d’un grand réfrigérateurL’apparence robuste du 516 a séduit BB&N, qui ne voulait pas qu’une bande d’étudiants vienne manipuler ses IMP. L’ordinateur était dépourvu de système d’exploitation, mais il manquait cruellement de RAM. Le logiciel de contrôle des IMP était écrit en langage assembleur du 516. L’un des développeurs était Will Crowther, qui allait créer le premier jeu d’aventure sur ordinateur .
Un autre obstacle subsistait avant que les IMP puissent être utilisés : la conception Honeywell manquait de certains composants nécessaires à la gestion des entrées et des sorties. Les employés de BB&N étaient consternés de constater que le premier 516, baptisé IMP-0, ne disposait pas de versions fonctionnelles des ajouts matériels demandés.
C’est Ben Barker, un brillant étudiant stagiaire chez BB&N, qui a dû réparer manuellement la machine. Barker était le meilleur choix, malgré une légère paralysie des mains. Après plusieurs journées stressantes de 16 heures à enrouler et dérouler des fils, toutes les modifications étaient terminées et fonctionnelles. L’IMP-0 était prêt.
Pendant ce temps, Steve Crocker, de l’Université de Californie à Los Angeles, travaillait sur un ensemble de spécifications logicielles pour les ordinateurs hôtes. Peu importe que les IMP soient parfaits pour envoyer et recevoir des messages si les ordinateurs eux-mêmes ne savaient pas quoi en faire. Les ordinateurs hôtes faisant partie d’importantes recherches universitaires, Crocker ne voulait pas passer pour un dictateur dictant aux utilisateurs ce qu’ils devaient faire de leurs machines. Il a donc intitulé son projet « Demande de commentaires », ou RFC.
Ce simple acte de politesse a changé à jamais la nature de l’informatique. Depuis, chaque modification a été effectuée sous forme de RFC, et la culture de la sollicitation de commentaires imprègne encore aujourd’hui le secteur technologique.
La RFC n° 1 proposait deux types de logiciels hôtes. Le premier était l’interface la plus simple possible, dans laquelle un ordinateur se faisait passer pour un terminal passif. On l’appelait « émulateur de terminal », et si vous avez déjà administré un serveur, vous en avez probablement utilisé un. Le second était un protocole plus complexe permettant de transférer des fichiers volumineux. C’est ainsi qu’est né le protocole FTP, toujours utilisé aujourd’hui.
Un seul IMP connecté à un ordinateur ne constituait pas un réseau à proprement parler. La livraison de l’IMP-1 à BB&N, puis son expédition par avion à UCLA en septembre 1969 furent donc très enthousiasmantes. Le premier test de l’ARPANET fut réalisé avec une assistance téléphonique simultanée. Le plan consistait à taper « LOGIN » pour lancer une séquence de connexion. Voici l’échange :
« As-tu eu le L ? »
« J’ai eu le L ! »
« As-tu eu le O ? »
« J’ai eu le O ! »
« Tu as eu le G ? »
« Oh non, l’ordinateur est tombé en panne ! »
Ce fut un début peu prometteur. L’ordinateur à l’autre bout du fil remplissait gentiment la partie « GIN » de « LOGIN », mais l’émulateur de terminal, n’attendant pas trois caractères à la fois, s’est bloqué. C’était la première fois que la saisie semi-automatique gâchait la journée de quelqu’un. Le bug a été corrigé et le test s’est terminé avec succès.
IMP-2, IMP-3 et IMP-4 ont été livrés au Stanford Research Institute (où Doug Engelbart souhaitait élargir sa vision de la connexion des personnes), à l’UC Santa Barbara et à l’Université de l’Utah.
Maintenant que le réseau de test à quatre nœuds était terminé, l’équipe de BB&N pouvait collaborer avec les chercheurs de chaque nœud pour tester l’ARPANET. Ils ont délibérément créé la toute première attaque par déni de service en janvier 1970, inondant le réseau de paquets jusqu’à son blocage brutal.
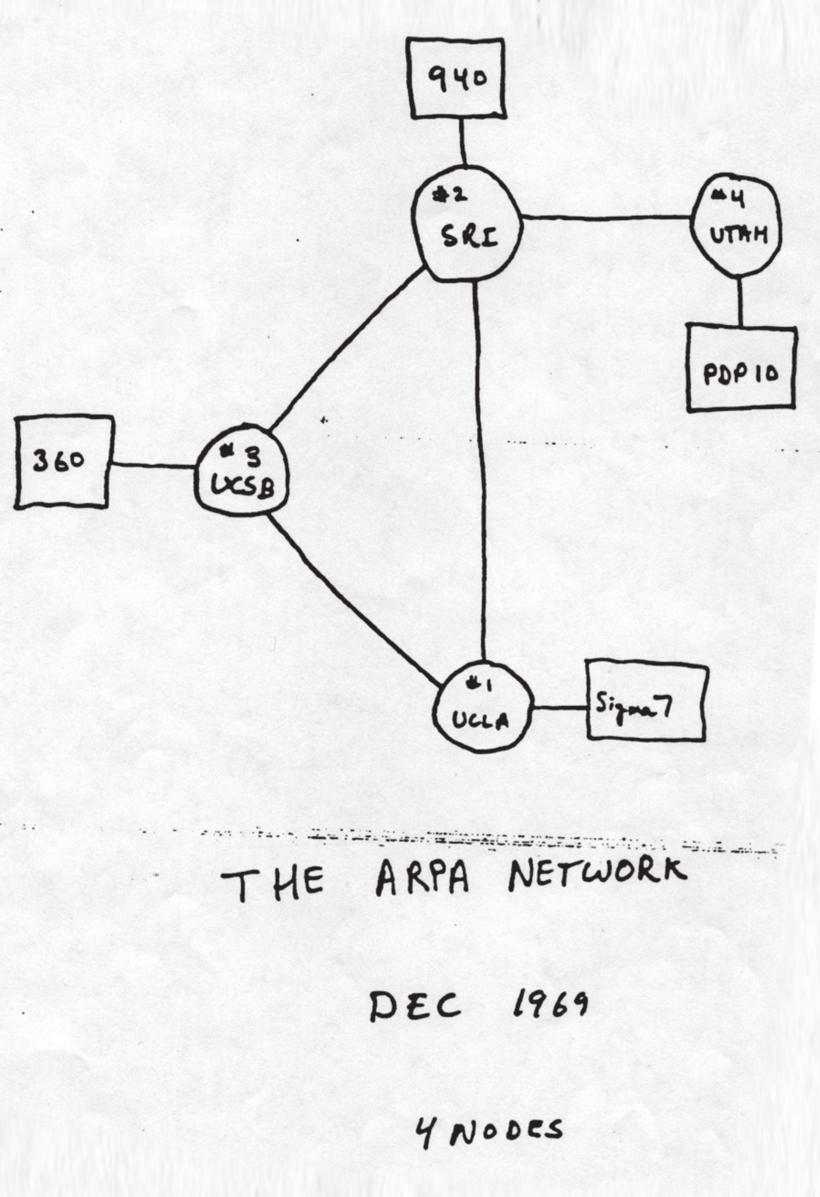
L’ARPANET original, prédécesseur d’Internet. Les cercles représentent des IMP et les rectangles des ordinateursÉtonnamment, de nombreux administrateurs des premiers nœuds ARPANET n’étaient pas enthousiastes à l’idée de rejoindre le réseau. L’idée que d’autres puissent utiliser les ressources de « leurs » ordinateurs les déplaisait. Taylor leur rappela que leurs projets matériels et logiciels étaient principalement financés par l’ARPA et qu’ils ne pouvaient donc pas s’en désengager.
Le mois suivant, Stephen Carr, Stephen Crocker et Vint Cerf ont publié la RFC n° 33. Elle décrivait un protocole de contrôle réseau (NCP) standardisant la communication entre les hôtes. Après son adoption, le réseau était opérationnel.

JCR Licklider, Bob Taylor, Larry Roberts, Steve Crocker et Vint CerfL’ARPANET s’est considérablement développé au cours des années suivantes. Parmi les événements marquants, on peut citer le tout premier échange de courriels entre deux ordinateurs, envoyé par Roy Tomlinson en juillet 1972. Une autre démonstration révolutionnaire a été réalisée à Harvard, avec un PDP-10 simulant en temps réel l’atterrissage d’un avion sur un porte-avions. Les données étaient transmises via l’ARPANET à un terminal graphique du MIT, et la vue graphique filaire était renvoyée à un PDP-1 à Harvard et affichée sur un écran. Bien que primitif et lent, il s’agissait techniquement du premier flux de jeu.
Un moment important se produisit en octobre 1972 lors de la Conférence internationale sur la communication par ordinateur. C’était la première fois que le réseau était présenté au public. L’intérêt pour ARPANET grandissait et l’enthousiasme était palpable. Un groupe de dirigeants d’AT&T remarqua une brève panne et rit, convaincus d’avoir raison en pensant que la commutation par paquets ne fonctionnerait jamais. Dans l’ensemble, la démonstration fut un succès retentissant.
Mais l’ARPANET n’était plus le seul réseau existant.

Les deux frappes sur un télétype modèle 33 qui ont changé l’histoireUn réseau de réseaux
Le reste du monde n’était pas resté inactif. À Hawaï, Norman Abramson et Franklin Kuo créèrent ALOHAnet , qui connectait les ordinateurs des îles par radio. Ce fut la première démonstration publique d’un réseau sans fil à commutation de paquets. Au Royaume-Uni, l’équipe de Donald Davies développa le réseau du National Physical Laboratory (NPL). Connecter ces réseaux semblait une bonne idée, mais ils utilisaient tous des protocoles, des formats de paquets et des débits de transmission différents. En 1972, les responsables de plusieurs projets de réseaux nationaux créèrent un Groupe de travail international sur les réseaux. Cerf fut choisi pour le diriger.
La première tentative pour combler cette lacune fut SATNET, également connu sous le nom d’Atlantic Packet Satellite Network. Grâce à des liaisons satellite, il connectait l’ARPANET américain aux réseaux britanniques. Malheureusement, SATNET utilisait ses propres protocoles. Fidèle à la tradition technologique, la tentative d’établir une norme universelle a créé une norme supplémentaire .
Robert Kahn a demandé à Vint Cerf de tenter de résoudre ces problèmes une fois pour toutes. Ils ont élaboré un nouveau protocole appelé Protocole de contrôle de transmission (TCP). L’idée était de connecter différents réseaux via des ordinateurs spécialisés, appelés « passerelles », qui traduisaient et transmettaient les paquets. TCP était comme une enveloppe pour les paquets, garantissant qu’ils parviendraient à la bonne destination sur le bon réseau. La fiabilité de certains réseaux n’étant pas garantie, lorsqu’un ordinateur recevait un message complet et intact, il renvoyait un accusé de réception (ACK) à l’expéditeur. Si l’ACK n’était pas reçu dans un certain délai, le message était retransmis.
En décembre 1974, Cerf, Yogen Dalal et Carl Sunshine rédigèrent une spécification complète pour TCP. Deux ans plus tard, Cerf et Kahn, avec une douzaine d’autres, présentèrent le premier système à trois réseaux. La démonstration connectait la radio par paquets, l’ARPANET et le SATNET, tous utilisant TCP. Par la suite, Cerf, Jon Postel et Danny Cohen suggérèrent une modification mineure, mais importante : ils devraient extraire toutes les informations de routage et les intégrer à un nouveau protocole, appelé protocole Internet (IP). Tous les éléments restants, comme le découpage et le réassemblage des messages, la détection des erreurs et la retransmission, resteraient dans TCP. Ainsi, en 1978, le protocole devint officiellement connu sous le nom de TCP/IP, et le restera à jamais.
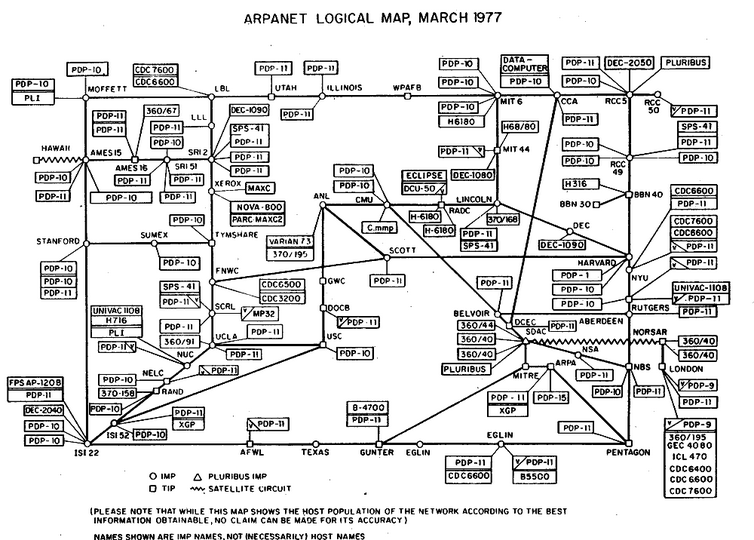
Carte d’Internet en 1977. Les points blancs représentent les IMP et les rectangles les ordinateurs hôtes. Les lignes irrégulières relient les autres réseauxSi l’histoire de la création d’Internet était un film, la sortie de TCP/IP en aurait été la conclusion triomphale. Mais les choses n’étaient pas si simples. Le monde était en pleine mutation, et le chemin à parcourir était, pour le moins, incertain.
À l’époque, rejoindre l’ARPANET nécessitait la location de lignes téléphoniques haut débit pour 100 000 dollars par an. Ce système était donc réservé aux grandes universités, aux entreprises de recherche et aux entreprises du secteur de la défense. Cette situation a conduit la National Science Foundation (NSF) à proposer un nouveau réseau plus économique à exploiter. D’autres réseaux éducatifs ont vu le jour à peu près à la même époque. S’il était logique de connecter ces réseaux à l’Internet en pleine expansion, rien ne garantissait que cela perdure. D’autres forces, plus importantes, étaient à l’œuvre.
À la fin des années 1970, les ordinateurs avaient considérablement progressé. L’invention du microprocesseur ouvrit la voie à des ordinateurs plus petits et moins chers qui commençaient tout juste à faire leur apparition dans les foyers. Les télétypes encombrants étaient remplacés par des terminaux élégants, semblables à des téléviseurs. Le premier service commercial en ligne, CompuServe , fut lancé en 1979. Pour seulement 5 dollars de l’heure, on pouvait se connecter à un réseau privé, consulter la météo et les bulletins financiers, et échanger des potins avec d’autres utilisateurs. Au départ, ces systèmes étaient totalement indépendants d’Internet. Mais leur croissance fut rapide. En 1987, CompuServe comptait 380 000 abonnés.

Une publicité dans un magazine pour CompuServe de 1980Entre-temps, l’adoption de TCP/IP n’était pas garantie. Au début des années 1980, le groupe Interconnexion des systèmes ouverts (OSI) de l’Organisation internationale de normalisation (ISO) a décidé que le monde avait besoin de davantage d’acronymes, ainsi que d’un nouveau modèle de réseau mondial et normalisé.
Le modèle OSI a été initialement élaboré en 1980, mais n’a été publié qu’en 1984. Néanmoins, de nombreux gouvernements européens, et même le ministère de la Défense américain, prévoyaient de passer de TCP/IP à OSI. Cette nouvelle norme semblait inévitable.

Le modèle OSI à sept couches. Si vous avez déjà pensé qu’il y avait trop de couches, vous n’êtes pas seul.Pendant que le monde attendait l’OSI, Internet continuait de croître et d’évoluer. En 1981, la quatrième version du protocole IP, IPv4, était lancée. Le 1er janvier 1983, l’ARPANET lui-même effectuait sa transition complète vers TCP/IP. Cette date est parfois qualifiée de « naissance d’Internet », même si, du point de vue de l’utilisateur, le réseau fonctionnait toujours comme il l’avait fait pendant des années.
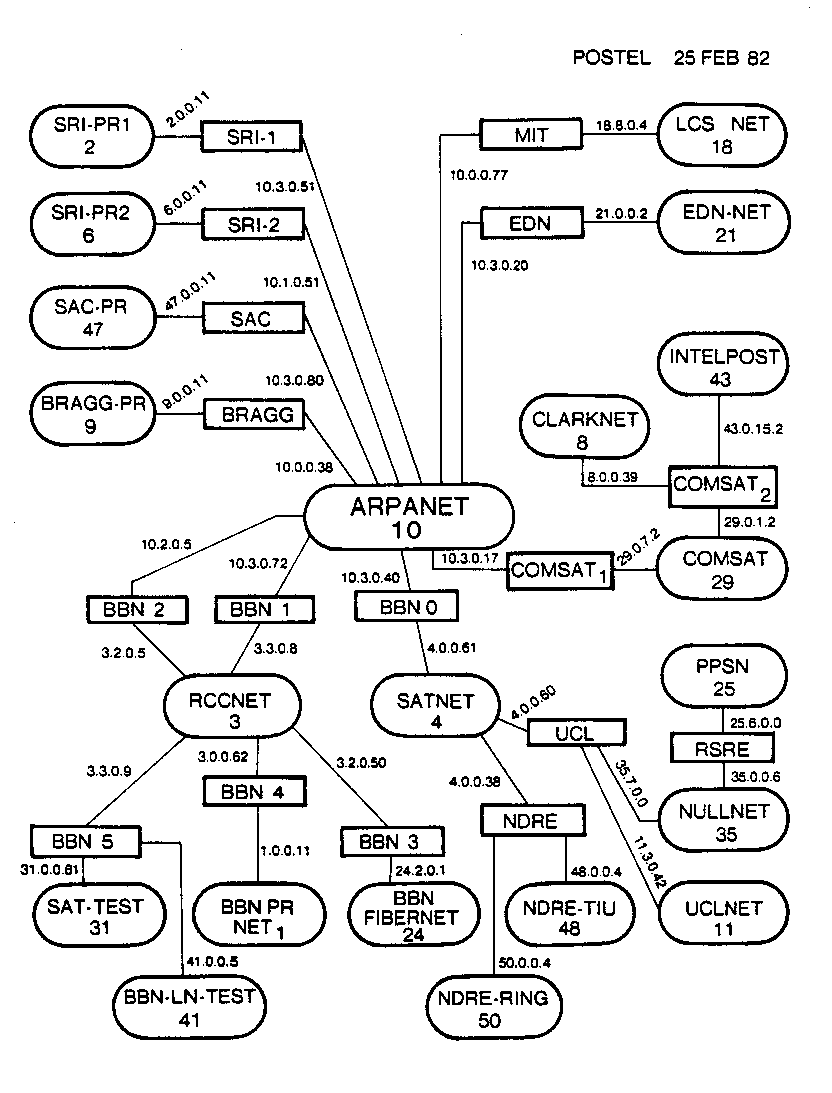
Carte d’Internet de 1982. Les ovales représentent les réseaux et les rectangles les passerelles. Les hôtes ne sont pas représentés, mais se comptent par centaines. Notez l’apparition d’adresses IPv4 modernesEn 1986, le NFSNET a été mis en ligne, fonctionnant sous TCP/IP et connecté au reste d’Internet. Il utilisait également une nouvelle norme, le système de noms de domaine (DNS). Ce système, toujours utilisé aujourd’hui, utilisait des noms faciles à mémoriser pour pointer vers l’adresse IP individuelle d’une machine. Les noms d’ordinateurs étaient attribués à des domaines de premier niveau en fonction de leur fonction. Ainsi, on pouvait se connecter à « frodo.edu » dans un établissement d’enseignement ou à « frodo.gov » dans un établissement public.
Le NFSNET a connu une croissance rapide, éclipsant l’ARPANET en taille. En 1989, l’ARPANET original a été mis hors service. Les IMP, obsolètes depuis longtemps, ont été retirés. Cependant, tous les hôtes ARPANET ont été migrés avec succès vers d’autres réseaux Internet. Tel un vaisseau de Thésée, l’ARPANET a survécu même après le remplacement de tous ses composants.
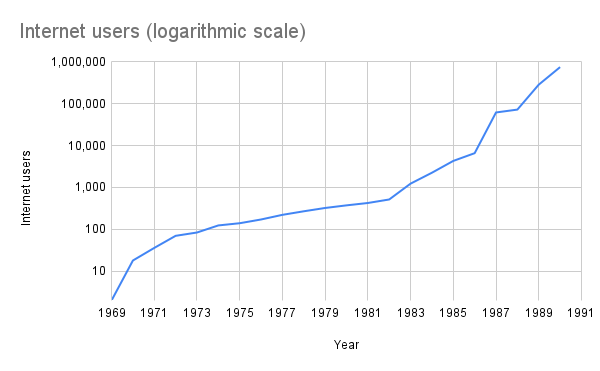
La croissance exponentielle de l’ARPANET/Internet au cours de ses deux premières décenniesPourtant, les experts et les commentateurs prédisaient que tous ces systèmes devraient à terme migrer vers le modèle OSI. Les créateurs d’Internet n’étaient pas convaincus. En 1987, dans la RFC n° 1 000 , Crocker déclarait : « Si nous avions consulté les anciens mystiques, nous aurions immédiatement compris que sept couches étaient nécessaires. »
Les pionniers d’Internet estimaient avoir passé de nombreuses années à peaufiner et à améliorer un système fonctionnel. Mais l’OSI était désormais doté d’une multitude de normes complexes et s’attendait à ce que tout le monde adopte sa nouvelle conception. Vint Cerf adoptait une vision plus pragmatique. En 1982, il quitta l’ARPA pour un nouveau poste chez MCI, où il participa à la création du premier système de messagerie électronique commercial (MCI Mail) connecté à Internet. Chez MCI, il contacta des chercheurs d’IBM, Digital et Hewlett-Packard et les convainquit d’expérimenter TCP/IP. Les dirigeants de ces entreprises continuèrent cependant de soutenir officiellement l’OSI.
Le débat fit rage durant la seconde moitié des années 1980 et jusqu’au début des années 1990. Lassé des débats interminables, Cerf contacta le directeur du National Institute of Standards and Technology ( NIST) et lui demanda de rédiger un rapport de synthèse comparant OSI et TCP/IP. Parallèlement, alors qu’il planifiait un successeur à IPv4, l’Internet Advisory Board (IAB) s’inspirait du protocole réseau sans connexion OSI et de son adressage 128 bits. Dans une interview accordée à Ars, Vint Cerf expliqua la suite des événements.
« Des extrémistes de l’IETF [Internet Engineering Task Force] ont délibérément mal interprété notre position, nous considérant comme des traîtres en adoptant l’OSI », a-t-il déclaré. « Ils ont fait grand bruit. L’IAB a été destitué et l’autorité du système a basculé. L’IAB était autrefois le décideur, mais la situation a basculé et l’IETF devient le standardisateur. »
Pour calmer les esprits, Cerf a fait un strip-tease lors d’une réunion de l’IETF en 1992. Il a dévoilé un t-shirt sur lequel était écrit « IP ON EVERYTHING ». Lors de la même réunion, David Clark a résumé le sentiment de l’IETF en déclarant : « Nous rejetons les rois, les présidents et le vote. Nous croyons au consensus approximatif et au code exécutable. »

Vint Cerf se réduit à l’essentielLe destin d’Internet
La conception divisée de TCP/IP, qui constituait un choix technique mineur à l’époque, a eu des implications politiques durables. En 2001, David Clark et Marjory Blumenthal ont rédigé un article retraçant la guerre des protocoles. Ils ont constaté que les fonctions complexes d’Internet étaient exécutées aux points terminaux, tandis que le réseau lui-même n’exécutait que la partie IP et se concentrait simplement sur le transfert de données. Ces « principes de bout en bout » ont constitué la base de « … la philosophie d’Internet » : liberté d’action, autonomisation des utilisateurs, responsabilité de l’utilisateur final pour ses actions et absence de contrôles sur le Net qui limitent ou régulent leurs actions », ont-ils déclaré.
En d’autres termes, la bataille entre TCP/IP et OSI ne se résumait pas à deux acronymes concurrents. D’un côté, un petit groupe d’informaticiens ayant passé de nombreuses années à construire un réseau relativement ouvert et souhaitant le voir perdurer sous leur propre direction bienveillante. De l’autre, un vaste collectif d’organisations puissantes estimaient devoir contrôler l’avenir d’Internet – et peut-être même le comportement de tous ses utilisateurs.
Mais ce débat impossible et le sort ultime d’Internet étaient sur le point d’être tranchés, et non par les gouvernements, les comités, ni même l’IETF. Le monde a été changé à jamais par l’action d’un homme. C’était un informaticien aux manières douces, né en Angleterre et travaillant pour un institut de recherche en physique en Suisse.
C’est l’histoire racontée dans le prochain article de notre série.
Source: https://arstechnica.com/gadgets/2025/04/a-history-of-the-internet-part-1-an-arpa-dream-takes-form/
Et pour la bande papier qu’on faisait défiler dans un lecteur ou perforer par un télétype:

L’alphabet tenait sur 5 bits en deux modes, le code “SHIFT”, permettait de passer de 32 catactères a l’autre jeu de chiffres et symboles de 32 caractères également, sans la moindre synchronisation, il fallait partir du bon pied pour lire correctement la bande et ne pas louper les trous. Certaines bandes pouvaient atteindre des longueurs surréalistes. Je n’ai malheureusement pas retrouvé le bruit caractéristique des ces antiqués, dommage, coté magie, ça valait le détour.
-
Histoire d’Internet, partie 2 : La ruée vers l’or de la haute technologie commence
En 1965, Ted Nelson soumit un article à l’Association for Computing Machinery. Il écrivit : « Permettez-moi d’introduire le terme “hypertexte” pour désigner un ensemble de documents écrits ou illustrés interconnectés de manière si complexe qu’il ne pourrait être présenté ou représenté aisément sur papier. » Cet article s’inscrivait dans une vision ambitieuse qu’il baptisa Xanadu, d’après le poème de Samuel Coleridge.
Dix ans plus tard, dans son livre « Dream Machines/Computer Lib », il décrivait Xanadu ainsi : « Vous offrir un écran chez vous d’où vous pourrez accéder aux bibliothèques hypertextes du monde. » Il admettait que le monde n’avait pas encore de bibliothèques hypertextes, mais que là n’était pas la question. Un jour, peut-être bientôt, cela arriverait. Et il allait consacrer sa vie à y parvenir.
Avec le développement d’Internet, il est devenu de plus en plus difficile d’y trouver des informations. Il existait de nombreux documents intéressants, comme le Guide du voyageur sur Internet , mais pour les lire, il fallait d’abord savoir où ils se trouvaient.
La communauté de programmeurs serviables sur Internet a relevé le défi. Alan Emtage, de l’Université McGill à Montréal, a développé un outil appelé Archie . Il consultait une liste de serveurs FTP publics. Il fallait toujours connaître le nom du fichier recherché, mais Archie permettait de le télécharger quel que soit le serveur sur lequel il se trouvait.
Un moteur de recherche amélioré, nommé Gopher à été développé par une équipe dirigée par Mark McCahill de l’Université du Minnesota. Il utilisait un système de menus textuels, évitant ainsi aux utilisateurs de mémoriser les noms et les emplacements des fichiers. Les serveurs Gopher pouvaient afficher une collection personnalisée de liens dans des menus imbriqués et s’intégraient à d’autres services comme Archie et Veronica pour faciliter la recherche de ressources supplémentaires.
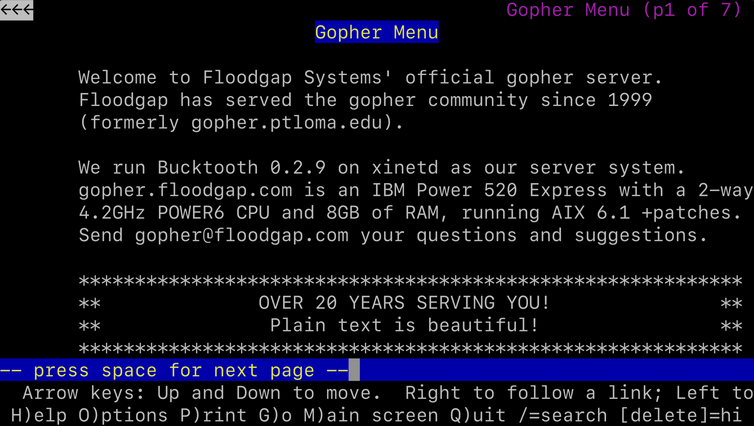
Un serveur Gopher pouvait fournir bon nombre des fonctionnalités que nous tenons pour acquises aujourd’hui : moteurs de recherche, pages personnelles contenant des liens et fichiers téléchargeables. Mais cela ne suffisait pas à un informaticien britannique travaillant au CERN , un institut intergouvernemental exploitant le plus grand laboratoire de physique des particules au monde.
Le World Wide Web
L’hypertexte avait beaucoup évolué depuis que Ted Nelson avait inventé le mot en 1965. Bill Atkinson, membre de l’équipe de développement du Macintosh, lança HyperCard en 1987. Ce logiciel utilisait l’interface graphique du Mac pour permettre à chacun de développer des « piles », des collections de textes, d’images et de sons, interconnectables par des liens cliquables. Il n’existait pas de réseau, mais les piles pouvaient être partagées avec d’autres utilisateurs en envoyant les fichiers sur une disquette.
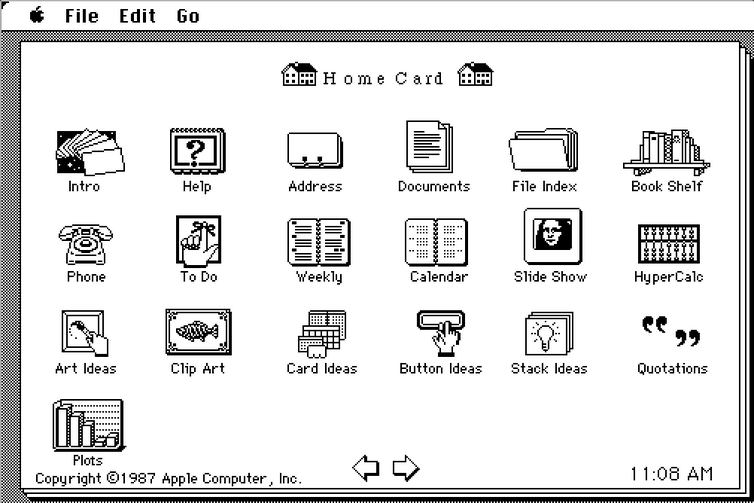
L’écran d’accueil de HyperCard 1.0 pour Macintosh
Hypercard est livré avec un tutoriel, écrit en Hypercard, expliquant son fonctionnement. Il y avait aussi des exemples d’applications, comme ce carnet d’adressesL’hypertexte était si important que des conférences furent organisées juste pour en discuter en 1987 et 1988. Même Ted Nelson avait enfin trouvé un sponsor pour son rêve personnel : le fondateur d’Autodesk, John Walker, avait accepté de créer une filiale pour créer une version commerciale de Xanadu.
C’est dans ce contexte que Tim Berners-Lee, boursier du CERN, a élaboré sa propre proposition en mars 1989 pour un nouvel environnement hypertexte. Son objectif était de faciliter la collaboration et le partage d’informations entre les chercheurs du CERN sur les nouveaux projets.
La proposition (qu’il baptisa « Mesh ») avait plusieurs objectifs. Elle fournirait un système permettant de connecter les informations relatives aux personnes, aux projets, aux documents et au matériel en cours de développement au CERN. Ce système serait décentralisé et réparti sur de nombreux ordinateurs. Tous les ordinateurs du CERN n’étaient pas identiques : on y trouvait des mini-équipements numériques sous VMS, des Macintosh et un nombre croissant de stations de travail Unix. Chacun d’eux devait pouvoir visualiser les informations de la même manière.
Comme l’a expliqué Berners-Lee : « Rares sont les produits qui mettent en pratique l’idée de Ted Nelson d’un vaste “docuunivers” en permettant des liens entre les nœuds de différentes bases de données. Pour y parvenir, une certaine normalisation serait nécessaire. »

Le document de proposition original pour le Web, écrit dans Microsoft Word pour Macintosh 4.0, téléchargé à partir du site Web de Tim Berners-LeeLe document concluait en qualifiant le projet de « pratique » et en estimant qu’il pourrait nécessiter six à douze mois de travail de deux personnes. Le responsable de Berners-Lee le qualifiait de « vague, mais passionnant ». Robert Cailliau, qui avait proposé de son propre chef un système hypertexte pour le CERN, rejoignit Berners-Lee pour commencer la conception du projet.
L’ordinateur utilisé par Berners-Lee était un NeXT Cube, produit par l’entreprise fondée par Steve Jobs après son licenciement d’Apple. Les stations de travail NeXT étaient chères, mais elles offraient un environnement de développement logiciel très en avance sur son temps. Si l’on pouvait s’en offrir une, c’était comme un accélérateur de code. John Carmack écrirait plus tard DOOM sur un NeXT.

La station de travail NeXT utilisée par Tim Berners-Lee pour créer le World Wide Web. Veuillez ne pas éteindre le World Wide WebBerners-Lee a baptisé son application « WorldWideWeb ». Le logiciel était composé d’un serveur, qui diffusait des pages de texte via un nouveau protocole appelé « Hypertext Transport Protocol » (HTTP), et d’un navigateur qui affichait le texte. Le navigateur traduisait le code de balisage comme « h1 » pour indiquer une police d’en-tête plus grande ou « a » pour indiquer un lien. Il existait également un éditeur de pages web graphique, mais il ne fonctionnait pas très bien et a été abandonné.
Le tout premier site Web a été publié, fonctionnant sur le cube de développement NeXT, le 20 décembre 1990. Quiconque possédait une machine NeXT et un accès à Internet pouvait voir le site dans toute sa splendeur.
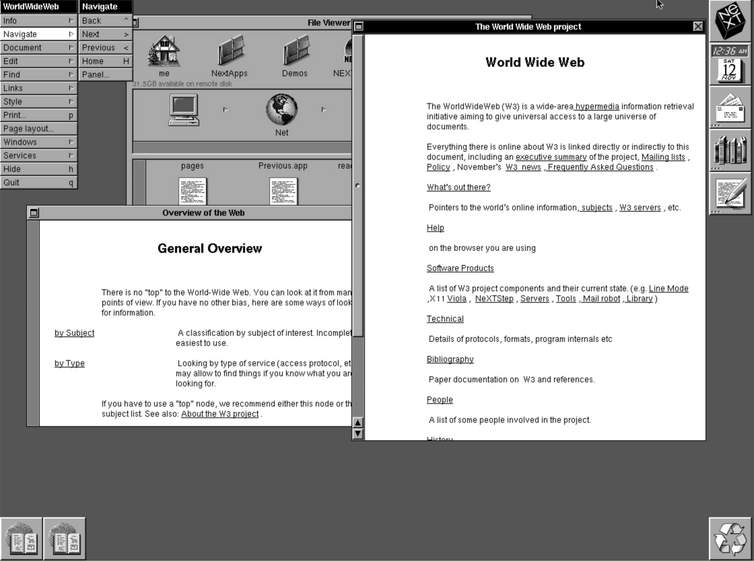
Le navigateur WorldWideWeb original fonctionnant sur NeXTstep 3, parcourant la première page Web au monde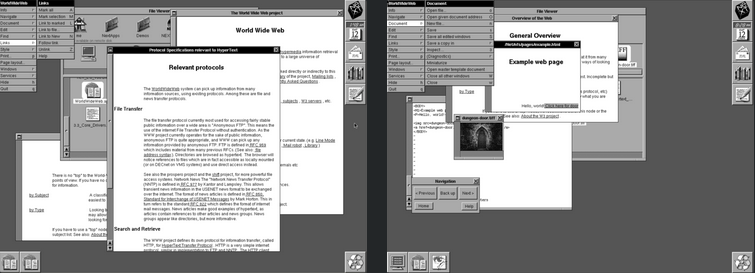
Cliquer sur des liens dans WorldWideWeb ouvrait de nouvelles fenêtres. Néanmoins, il existait des options pour naviguer vers l’avant, l’arrière et le haut. Il n’y avait pas d’images intégrées. Cependant, il était possible de créer des liens vers des images qui apparaissaient dans une nouvelle fenêtre, à condition qu’il s’agisse de fichiers TIFFComme NeXT n’a vendu que 50 000 ordinateurs au total, ce croisement ne représentait pas beaucoup de monde. Huit mois plus tard, Berners-Lee a répondu à une question sur des projets intéressants sur le groupe de discussion Usenet alt.hypertext. Il a décrit le projet World Wide Web et a inclus des liens vers tous les logiciels et la documentation.
Ce message a changé le monde pour toujours.
Mosaic
Le 9 décembre 1991, le président George H.W. Bush a promulgué la loi sur le calcul haute performance (High Performance Computing Act) , également connue sous le nom de loi Gore. Cette loi finançait la mise à niveau du réseau dorsal NSFNET, ainsi qu’une initiative de financement distincte pour le Centre national des applications de supercalcul ( NCSA ).
Le NCSA, basé à l’Université de l’Illinois, est devenu un lieu de rêve pour la recherche informatique. « Le NCSA était un paradis », se souvient Alex Totic, qui y était étudiant. « Ils avaient tout ce qu’il fallait, des machines pensantes aux Crays, en passant par les Mac et les réseaux. C’était génial. » Comme souvent dans le monde universitaire, les professeurs proposaient des idées de recherche, mais confiaient la majeure partie du travail à leurs étudiants de troisième cycle.
Parmi ces étudiants figurait Marc Andreessen, qui avait rejoint NCSA comme programmeur à temps partiel pour 6,85 dollars de l’heure. Andreessen était fasciné par le Web, et plus particulièrement par les navigateurs. Un nouveau navigateur pour ordinateurs Unix, ViolaWWW , faisait son apparition au NCSA. Dépassant désormais les limites du poste de travail NeXT, le Web avait captivé la communauté Unix. Mais cette communauté était encore trop restreinte pour Andreessen.
« Pour utiliser le Net, il fallait comprendre Unix », a-t-il déclaré lors d’une interview avec Forbes. « Et les utilisateurs actuels ne cherchaient absolument pas à simplifier les choses. En fait, ils ne voulaient absolument pas simplifier les choses, ils voulaient même tenir la racaille à l’écart. »
Andreessen a fait appel à son collègue programmeur Eric Bina et a commencé à développer un nouveau navigateur web en décembre 1992. En un peu plus d’un mois, ils ont publié la version 0.5 de « NCSA X Mosaic », ainsi nommée car elle était conçue pour fonctionner avec le système X Window d’Unix. Des portages pour Macintosh et Windows ont suivi peu après.
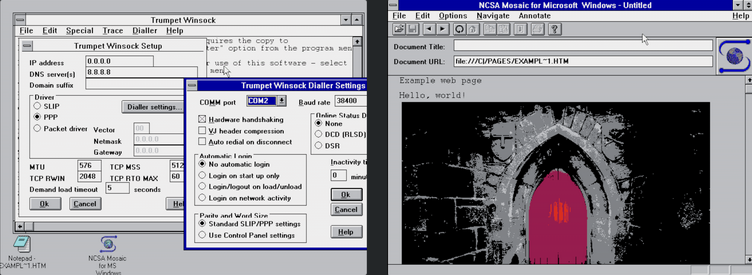
Il n’était pas facile de faire fonctionner Mosaic sur un ordinateur Windows en 1993. Il fallait acheter et configurer une application TCP/IP tierce, comme Trumpet Winsock, avant même que Mosaic ne démarre. Mais une fois le système lancé, le Web est devenu beaucoup plus simple et plus intéressant à utiliser. Mosaic a ajouté la balise permettant d’afficher des images au sein des pages web, à condition qu’elles soient au format GIF. Le format GIF a été inventé par CompuServeÊtre disponible sur les ordinateurs graphiques les plus populaires a changé la trajectoire du web. En seulement 18 mois, des millions d’exemplaires de Mosaic ont été téléchargés, et le rythme s’est accéléré. La racaille était là pour durer.
Netscape
Le succès immédiat de Mosaic a suscité un intérêt accru de la part de la direction de NCSA pour le projet. Jon Mittelhauser, co-auteur de la version Windows, se souvient que la petite équipe « s’est soudainement retrouvée en réunion avec quarante personnes pour planifier nos prochaines fonctionnalités, au lieu de cinq personnes à planifier à 2 heures du matin devant une pizza et un Coca ».
On a demandé à Andreessen de se retirer et de laisser des managers plus expérimentés prendre la relève. Il a donc quitté NCSA et s’est installé en Californie, à la recherche d’une nouvelle opportunité. « Je pensais avoir tout raté », a déclaré Andreessen . « À mon arrivée, l’ambiance générale dans la Vallée était que le PC était fini, et d’ailleurs, la Vallée était probablement finie parce qu’il n’y avait plus rien à faire. »
Mais sa réputation l’avait précédé. Jim Clark, le fondateur de Silicon Graphics , cherchait lui aussi à se lancer dans une aventure. Un ami lui avait montré une démo de Mosaic, et Clark avait contacté Andreessen pour le rencontrer.
Lors d’une réunion, Andreessen lança l’idée de créer un « tueur de Mosaic ». Il montra à Clark un graphique montrant que le nombre d’utilisateurs web doublait tous les cinq mois. Enthousiasmés par les possibilités offertes, les deux hommes fondèrent Mosaic Communications Corporation le 4 avril 1994. Andreessen recruta rapidement des programmeurs au sein de son ancienne équipe, et ils se mirent au travail. Ils baptisèrent leur nouveau navigateur « Mozilla », car il s’agissait d’un monstre capable de dévorer Mosaic. Les versions bêta furent baptisées « Mosaic Netscape », mais l’Université de l’Illinois menaça de poursuivre la nouvelle entreprise en justice. Pour éviter tout litige, le nom de l’entreprise et du navigateur fut changé en Netscape, et les programmeurs auditèrent leur code pour s’assurer qu’il n’avait pas été copié de NCSA.
Netscape est devenu le modèle à suivre pour toutes les startups Internet. Les programmeurs bénéficiaient de sodas gratuits à volonté et étaient encouragés à ne pratiquement jamais quitter leur bureau. « Netscape Time » a accéléré les calendriers de développement logiciel, et comme les mises à jour pouvaient être diffusées via Internet, les anciens principes d’assurance qualité ont disparu. Et le modèle économique ? Il consistait simplement à « prospérer rapidement », les profits pouvant être calculés ultérieurement.
Les travaux ont progressé rapidement et la version 1.0 de Netscape Navigator et du serveur web Netsite a été lancée le 15 décembre 1994 pour les systèmes Windows, Macintosh et Unix sous X Windows. Le navigateur était vendu 39 $ pour les utilisateurs commerciaux, mais il était gratuit pour « l’utilisation académique et non commerciale, ainsi que pour une évaluation gratuite ».
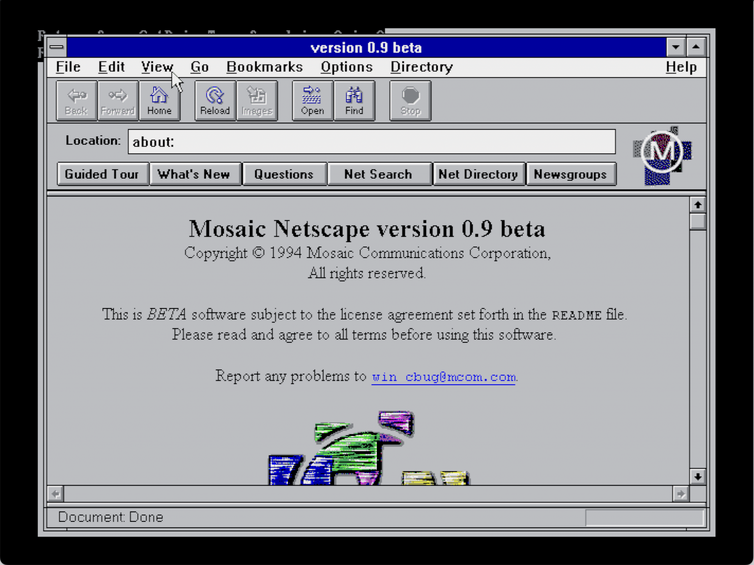
La version 0.9 s’appelait « Mosaic Netscape » et le logo et l’entreprise étaient toujours Mosaic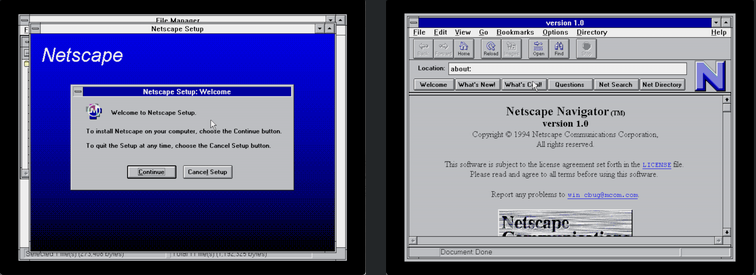
La version 1.0 s’appelait simplement Netscape, même si l’ancien logo s’était glissé dans l’écran d’installation. Le nouveau logo était un N géant. Les images ont été téléchargées progressivement, rendant la navigation beaucoup plus rapideNetscape est rapidement devenu la référence. En six mois, il a conquis plus de 70 % du marché des navigateurs web. Le 9 août 1995, seulement 16 mois après sa création, Netscape a déposé son dossier d’introduction en bourse. Une décision de dernière minute a doublé le prix de l’action à 28 dollars et, dès le premier jour de cotation, l’action a grimpé à 75 dollars pour clôturer à 58,25 dollars. L’ère du Web était officiellement arrivée.
Le Web combat les solutions propriétaires
L’engouement suscité par une nouvelle façon de transmettre du texte et des images au public par téléphone ne se limitait pas au Web. Les systèmes commerciaux en ligne comme CompuServe évoluaient également pour s’adapter à l’ère graphique. Ces entreprises proposaient de nouvelles interfaces attrayantes pour leurs services, fonctionnant sur DOS, Windows et Macintosh. De nouveaux services exclusivement graphiques étaient également apparus, comme Prodigy , fruit d’une collaboration entre IBM et Sears, et une start-up née des cendres d’un service Commodore 64 appelé Quantum Link : America Online, ou AOL.
Même Microsoft s’y mettait. Bill Gates croyait que les « autoroutes de l’information » étaient l’avenir de l’informatique et voulait s’assurer que toutes les routes passent par le péage de son entreprise. Le très attendu Windows 95 devait être livré avec un service d’accès à distance en ligne intégré, appelé Microsoft Network, ou MSN.
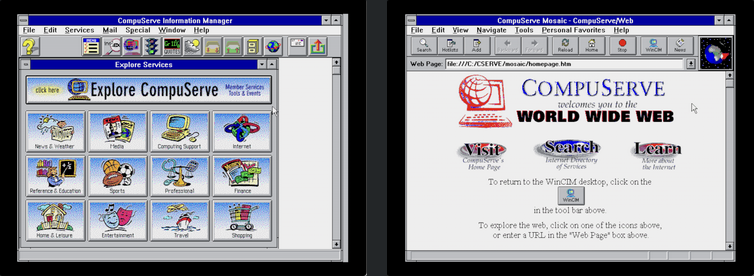
Le gestionnaire d’informations CompuServe a ajouté une interface graphique au service, ce qui a permis de réduire les frais de connexion horaires. CompuServe Information Manager était également livré avec une version personnalisée du navigateur Web Mosaic, qui permettait aux utilisateurs de surfer sur le Web tout en étant connectés à CompuServe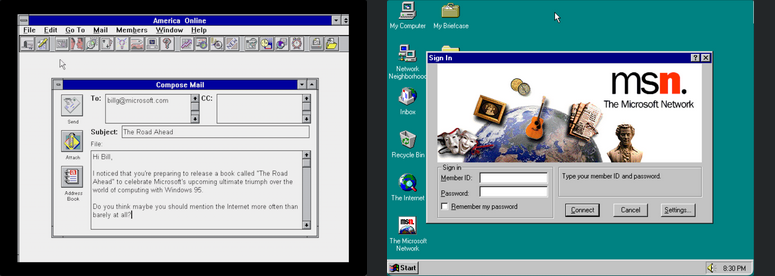
America Online était un nouveau service graphique en ligne qui permettait, entre autres, d’envoyer des courriels à n’importe qui sur Internet. Très populaire aux États-Unis, il l’était moins dans le reste du monde. La réponse de Microsoft aux services comme CompuServe et AOL était le réseau Microsoft, fourni avec Windows 95Au début, on ne savait pas lequel de ces services en ligne sortirait vainqueur. Mais on supposait qu’au moins l’un d’entre eux parviendrait à vaincre l’Internet complexe et intello. CompuServe était le plus ancien, mais AOL, plus agile, a connu le succès en envoyant gratuitement des millions de disques de démarrage (et plus tard de CD) à ses clients potentiels. Microsoft était convaincu que l’intégration de MSN avec le futur Windows 95 lui assurerait la victoire.
La plupart de ces services ont décidé de se protéger en ajoutant une sorte d’« accès annexe » au Web. Après tout, s’ils ne le faisaient pas, leurs concurrents le feraient. Parallèlement, de plus petites entreprises (dont beaucoup étaient d’anciens services de forums électroniques ) ont commencé à devenir des fournisseurs d’accès à Internet. Ces petits « FAI » pouvaient facturer moins cher que les grands services, car ils n’avaient pas à créer de contenu eux-mêmes. Des milliers de nouveaux sites web apparaissaient chaque jour sur Internet, bien plus vite que l’ajout de nouvelles sections à AOL ou CompuServe.
Le tournant est survenu très rapidement. Avant même la sortie de Windows 95, Bill Gates rédigeait son célèbre mémo « Internet Tidal Wave », dans lequel il attribuait à Internet la plus haute importance. MSN est rapidement devenu un fournisseur d’accès Internet standard et a transféré tout son contenu sur le Web. Microsoft s’est empressé de lancer son propre navigateur web, Internet Explorer, et l’a intégré au Pack Windows 95 Plus.
L’engouement et l’élan étaient désormais entièrement tournés vers le Web. C’était la technologie la plus passionnante et la plus transformatrice de son époque. La bataille de dix ans pour contrôler Internet en imposant le passage à un nouveau modèle de normes OSI était oubliée. Le Web était devenu la seule préoccupation, et il fonctionnait sur TCP/IP.
La guerre des navigateurs
Netscape n’avait jamais espéré générer autant de revenus grâce à son navigateur, car on supposait que la plupart des utilisateurs continueraient à télécharger gratuitement de nouvelles versions « d’évaluation ». Les dirigeants furent agréablement surpris lorsque les entreprises commencèrent à envoyer des chèques colossaux à Netscape. Le chiffre d’affaires de l’entreprise passa de 17 millions de dollars en 1995 à 346 millions de dollars l’année suivante, et la presse commença à surnommer Marc Andreessen « le nouveau Bill Gates ».
L’ancien Bill Gates n’en voulait pas. Suite à sa note de 1995, Microsoft s’efforça d’améliorer Internet Explorer et le rendit disponible gratuitement, y compris pour les utilisateurs professionnels. Netscape tenta de riposter. Il ajouta de nouvelles fonctionnalités révolutionnaires comme JavaScript , inspiré de LISP mais avec une syntaxe proche de Java, le nouveau langage de programmation à la mode de Sun Microsystems. Mais il était difficile de concurrencer le libre, et la part de marché de Netscape commença à chuter. En 1996, les deux navigateurs avaient atteint la version 3.0 et étaient à peu près équivalents en termes de fonctionnalités. La bataille continua, mais lorsque l’ Apache Software Foundation lança son serveur web gratuit, l’autre source de revenus de Netscape s’épuisa également. La situation était grave.

En 1996, il n’y avait pas de meilleure façon de déclarer votre allégeance à un navigateur Web qu’en ajoutant « Meilleur affichage dans » au-dessus de l’une de ces icônesLe boom des dot-com
En 1989, la NSF a levé les restrictions sur l’accès commercial à Internet et, en 1991, elle avait supprimé tous les obstacles aux échanges commerciaux sur le réseau. Avec l’essor soudain du Web, grâce à Mosaic, Netscape et Internet Explorer, de nouvelles entreprises se sont lancées dans cette ruée vers l’or de la haute technologie. Mais au départ, la meilleure stratégie commerciale n’était pas claire. Les utilisateurs s’attendaient à ce que tout sur le Web soit gratuit ; alors, comment gagner de l’argent ?
Nombre des premières entreprises web ont vu le jour par pur loisir. En 1994, Jerry Yang et David Filo étaient doctorants en génie électrique à l’université de Stanford. Après le succès de Mosaic, ils ont commencé à collecter et à échanger des liens vers de nouveaux sites web. C’est ainsi que naquit « Le guide du Web de Jerry », fonctionnant sur la station de travail Sun de Yang. Rebaptisé Yahoo! (Yet Another Hierarchical, Officious Oracle), le site connut une popularité fulgurante. Netscape intégra plusieurs liens vers Yahoo dans sa barre de navigation principale, ce qui accéléra encore la croissance. « Nous n’étions pas vraiment certains que cela puisse devenir une entreprise », confia Yang à Fortune. Malgré tout, des sociétés de capital-risque se présentèrent. Sequoia, qui avait gagné des millions en investissant dans Apple, investit 1 million de dollars pour acquérir 25 % de Yahoo.
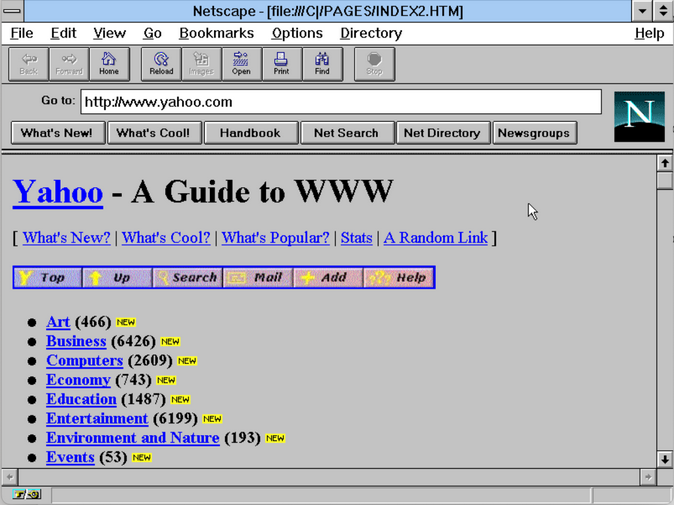
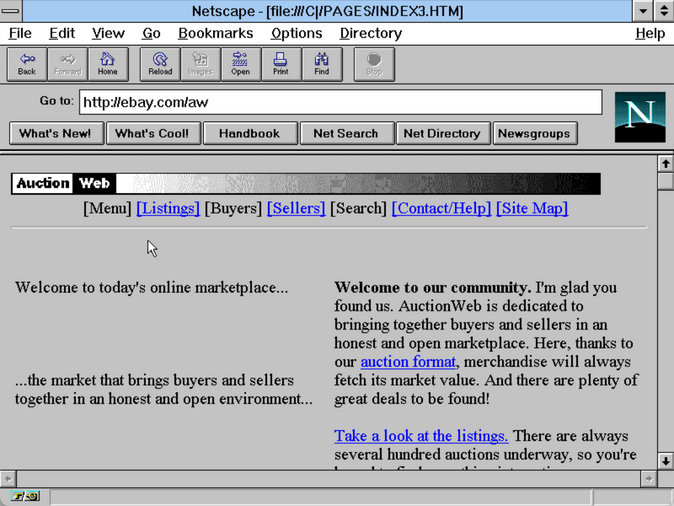
Yahoo.com tel qu’il aurait pu apparaître en 1995Un autre site de loisirs, AuctionWeb, a été lancé en 1995 par Pierre Omidyar. Fonctionnant sur son propre serveur et utilisant l’abonnement mensuel standard de son FAI à 30 $, le site permettait d’acheter et de vendre des objets de presque toutes sortes. Lorsque le trafic a commencé à augmenter, son FAI lui a annoncé qu’il augmentait ses frais d’accès à Internet à 250 $ par mois, conformément aux exigences d’une entreprise commerciale. Omidyar a décidé d’en faire une véritable entreprise, même s’il n’avait pas de compte marchand pour les cartes de crédit ni même de moyen de faire appliquer les nouvelles redevances de 5 % ou 2,5 %. Peu importe, car les recettes ont commencé à affluer. Il a trouvé un partenaire commercial, a changé le nom pour eBay, et le reste appartient à l’histoire.
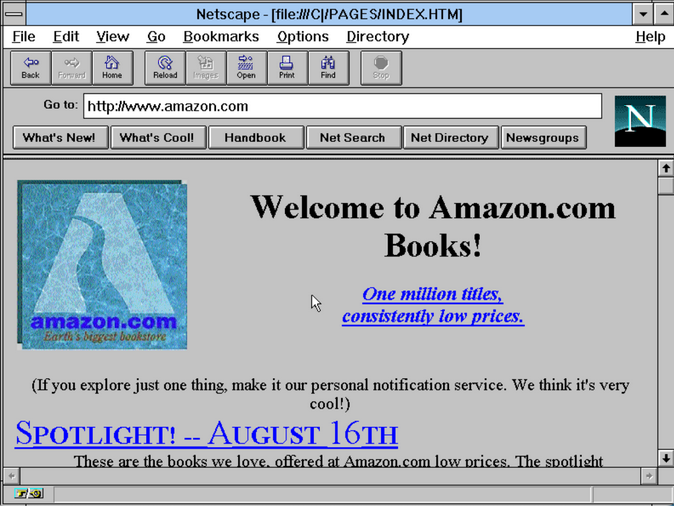
AuctionWeb (plus tard eBay) tel qu’il aurait pu apparaître en 1995En 1993, Jeff Bezos, vice-président senior d’un fonds spéculatif, fut chargé d’étudier les opportunités commerciales sur Internet. Il décida de réaliser la preuve de concept de ce qu’il qualifia de « magasin de tout ». Il choisit les livres comme produit idéal à vendre en ligne, car un livre vendu dans une librairie était identique à un autre, et un site web pouvait donner accès à des titres méconnus, potentiellement indisponibles en librairie physique.
Il quitta le fonds spéculatif, rassembla des investisseurs et des développeurs de logiciels talentueux et s’installa à Seattle. C’est là qu’il créa Amazon. Au départ, le site n’était guère plus qu’une version en ligne d’un catalogue de librairie existant, appelé Books In Print. Mais au fil du temps, Bezos y ajouta les données d’inventaire des deux principaux distributeurs de livres, Ingram et Baker & Taylor. La promesse d’accéder à tous les livres du monde était enthousiasmante, et l’entreprise connut une croissance rapide.
Amazon.com tel qu’il aurait pu apparaître en 1995La croissance explosive de ces startups a alimenté un cercle vicieux. Alors que des publications comme Wired expérimentaient des versions en ligne de leurs magazines, elles ont inventé et vendu des bannières publicitaires pour financer leurs sites web. Les meilleurs clients pour ces publicités étaient d’autres startups web. Ces entreprises souhaitaient augmenter leur trafic et savaient que les publicités sur des sites comme Yahoo étaient le meilleur moyen d’y parvenir. Les commerciaux de Yahoo ont alors pu démontrer la performance exponentielle de leurs ventes publicitaires, ce qui a entraîné la hausse de l’action Yahoo. Cela a encouragé le financement de nouvelles startups web, qui auraient toutes dû faire de la publicité sur Yahoo. Ces nouvelles startups ont également dû acheter des serveurs à des entreprises comme Sun Microsystems, ce qui a également entraîné la hausse de l’action Yahoo.
Le crash
Dans la seconde moitié des années 1990, tout semblait aller pour le mieux. L’économie était en plein essor, notamment grâce à l’essor du Web et à l’énorme essor qu’il a donné aux fabricants de matériel informatique et de logiciels. L’indice NASDAQ des valeurs technologiques a clairement illustré ce boom.
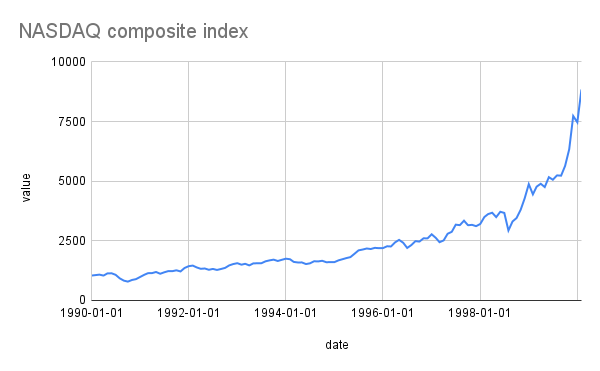
L’indice composite NASDAQ dans les années 1990Le président de la Réserve fédérale, Alan Greenspan, a qualifié ce phénomène d’« exubérance irrationnelle », mais ne semblait pas pressé de l’enrayer. Le fait que la plupart des jeunes startups du web n’aient pas de modèle économique réaliste ne semblait pas gêner les investisseurs. Certes, WebVan payait peut-être plus pour livrer ses courses qu’elle ne gagnait auprès de ses clients, mais regardez sa courbe de croissance !
L’exubérance ne pouvait durer éternellement. Le NASDAQ a culminé à 8 843,87 en février 2000, puis a commencé à baisser. En un mois, il a perdu 34 % de sa valeur et, en août 2001, il était tombé à 3 253,38. Les entreprises du web ont licencié ou ont complètement fermé leurs portes. La fête était finie.
Andreessen a déclaré que le krach technologique l’avait marqué. « Au début des années 90, le message le plus fort adressé à notre génération était : “Vous êtes des sales types, vous êtes à fond dans le grunge, vous êtes des ratés !” Puis le boom technologique a frappé, et on nous a dit : “On va faire des choses incroyables !” Et puis le plafond s’est effondré, et la sagesse nous a appris qu’Internet n’était qu’un mirage. J’y ai cru à 100 %, car le rejet était tellement personnel – à la fois ce que les autres pensaient de moi et ce que je pensais de moi-même. »
Mais tandis que certaines entreprises célébraient en silence la fin d’Internet, d’autres renaîtraient des cendres de l’effondrement de la bulle Internet. C’est le sujet de notre troisième et dernier article.
Source et légérement plus: https://arstechnica.com/gadgets/2025/06/a-history-of-the-internet-part-2-the-high-tech-gold-rush-begins/
-
Histoire d’Internet, partie 3 : L’essor de l’utilisateur
Les rênes de l’Internet sont confiées aux utilisateurs ordinaires, avec des résultats inégaux.

Larry Page et Sergey Brin se sont rencontrés lors d’une séance d’orientation pour étudiants de troisième cycle à Stanford en 1996. Tous deux préparaient leur doctorat en informatique et s’intéressaient à l’analyse de grands volumes de données. Face à l’essor rapide du Web, ils ont décidé de lancer un projet visant à améliorer la recherche d’informations sur Internet.
Ils n’étaient pas les premiers à tenter cette expérience. Les sites soigneusement sélectionnés comme Yahoo avaient déjà cédé la place à des moteurs de recherche plus algorithmiques comme AltaVista et Excite, tous deux lancés en 1995. Ces sites tentaient de trouver des pages web pertinentes en analysant les mots clés de chaque page.
La technique de Page et Brin était différente. Leur logiciel « BackRub » créait une carte de tous les liens que les pages avaient entre elles. Les pages sur un sujet donné qui généraient de nombreux liens entrants provenant d’autres sites obtenaient un meilleur classement pour ce mot-clé. Les pages mieux classées pouvaient alors contribuer à un score plus élevé pour les pages vers lesquelles elles pointaient. En un sens, cela s’apparentait à une externalisation participative de la recherche : lorsque les internautes saisissaient « C’est un bon endroit pour lire sur les alligators » sur un site populaire et ajoutaient un lien vers une page consacrée aux alligators, cela permettait de mieux déterminer la pertinence de cette page que de simplement compter le nombre d’apparitions du mot sur une page.
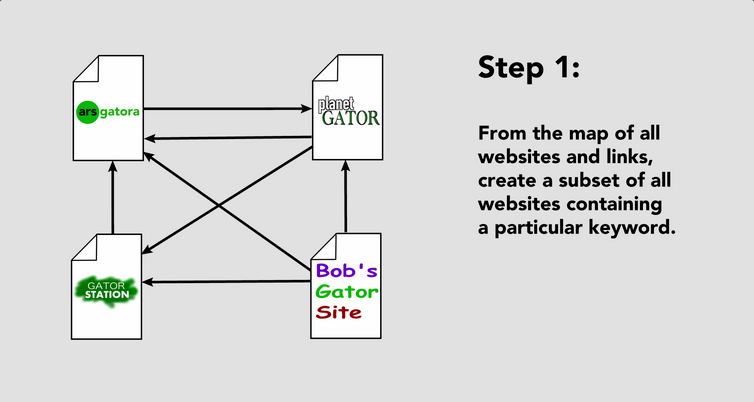
Étape 1 de l’algorithme BackRub simplifié. Il enregistre également la position de chaque mot sur une page, ce qui permet de créer un sous-ensemble supplémentaire pour plusieurs mots apparaissant côte à côte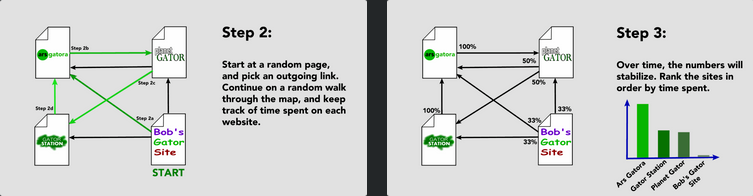
Étape 2 de l’algorithme BackRub simplifié. Mathématiquement, cette « marche aléatoire » est appelée chaîne de Markov. Étape 3 de l’algorithme BackRub simplifié. Il arrive que le message soit bloqué dans de petits groupes sans issue ; dans 15 % des cas, il passe à une autre page aléatoireCréer une carte connectée de l’ensemble du Web, avec des index pour chaque mot, nécessitait une puissance de calcul considérable. Le duo a rempli ses chambres universitaires de tous les ordinateurs qu’ils ont pu trouver, financés par une subvention de 10 000 dollars du Stanford Digital Libraries Project. Nombre d’entre eux ont été bricolés à partir de pièces détachées, dont un avec un boîtier imitant des briques LEGO. Leur projet de web scraping était si gourmand en bande passante qu’il a brièvement perturbé le réseau interne de l’université. N’ayant aucun talent de designer, ils ont codé la « page d’accueil » la plus simple possible en HTML.
En août 1996, BackRub était disponible via un lien sur le site web de Stanford. Un an plus tard, Page et Brin rebaptisaient le site « Google ». Ce nom était une faute d’orthographe accidentelle de googol, un terme inventé par le jeune fils d’un mathématicien pour décrire un 1 suivi de 100 zéros. Déjà à l’époque, le duo voyait grand.
Google.com tel qu’il apparaissait en 1998 sous windows xp et ses superbes icônesMi-1998, leur prototype enregistrait plus de 10 000 recherches par jour. Page et Brin comprirent qu’ils tenaient peut-être un projet ambitieux. L’explosion de la bulle Internet approchait, et ils cherchèrent donc du capital-risque pour créer une nouvelle entreprise.
Mais à l’époque, les moteurs de recherche étaient considérés comme dépassés. La nouvelle tendance était aux portails, des sites proposant des fonctionnalités de recherche, mais fortement axés sur le contenu sponsorisé. Après tout, c’est là que se trouvaient les plus grosses sommes d’argent. Page et Brin ont tenté de vendre la technologie à AltaVista pour 1 million de dollars, mais sa société mère a refusé. Excite et Yahoo ont également refusé.
Frustrés, ils décidèrent de se replier sur eux-mêmes et de continuer à améliorer leur produit. Brin créa un logo coloré avec le logiciel de dessin gratuit GIMP, et ils ajoutèrent un extrait de résumé à chaque résultat. Finalement, le duo reçut 100 000 dollars de l’investisseur providentiel Andy Bechtolsheim, cofondateur de Sun Microsystems. Cela suffisit à lancer l’entreprise.
Page et Brin étaient prudents avec leur argent, même après avoir reçu des millions supplémentaires de sociétés de capital-risque. Ils privilégiaient le matériel informatique bon marché et le système d’exploitation gratuit Linux pour développer leur système. Pour le marketing, ils comptaient principalement sur le bouche-à-oreille. C’est ce qui a permis à Google de survivre à l’effondrement de la bulle Internet qui a paralysé ses concurrents.
Pourtant, l’entreprise a finalement dû trouver une source de revenus. Les fondateurs craignaient que l’influence de la publicité sur les résultats de recherche puisse en réduire l’utilité et la précision. Ils ont trouvé un compromis en ajoutant de courtes annonces textuelles, clairement identifiées comme « Liens sponsorisés ». Pour réduire les coûts, ils ont créé un formulaire permettant aux annonceurs de soumettre leurs propres annonces et de les voir apparaître en quelques minutes. Ils ont même ajouté un système de classement pour que les annonces les plus populaires apparaissent en tête de liste.
La combinaison d’un produit supérieur et de publicités moins intrusives a propulsé Google vers des sommets vertigineux. En 2024, l’entreprise a généré plus de 350 milliards de dollars de chiffre d’affaires, dont 112 milliards de dollars de bénéfices.
L’information veut être libre
Au départ, le Web était essentiellement composé de texte et d’images occasionnelles. En 1997, Netscape a ajouté la possibilité d’intégrer de petits fichiers musicaux au format MIDI, qui étaient lus au chargement d’une page web. Comme ces morceaux n’étaient encodés que par des notes, leur son était métallique et gênant sur la plupart des ordinateurs. Un bon son ou des chansons avec voix nécessitaient des fichiers trop volumineux pour être téléchargés sur Internet.
Mais tout cela a changé avec un nouveau format de fichier. En 1993, des chercheurs de l’Institut Fraunhofer ont développé une technique de compression permettant d’éliminer les parties audio indétectables par l’oreille humaine. La chanson « Tom’s Diner » de Suzanne Vega a servi de premier test à la nouvelle norme MP3.
Désormais, les ordinateurs pouvaient lire des chansons de qualité raisonnable à partir de petits fichiers grâce à des décodeurs logiciels. WinPlay3 fut le premier, mais WinAmp, sorti en 1997, devint le plus populaire. Les utilisateurs commencèrent à publier des liens vers des fichiers MP3 sur leurs sites web personnels. Puis, en 1999, Shawn Fanning lança la version bêta d’un produit qu’il appela Napster. Il s’agissait d’une application de bureau qui s’appuyait sur Internet pour permettre aux utilisateurs de partager leur collection MP3 et de rechercher celle des autres.
Napster tel qu’il aurait pu apparaître en 1999Napster s’est presque immédiatement heurté à des poursuites judiciaires de la part de la Recording Industry Association of America (RIAA). Cela a déclenché un débat sur le partage de contenu sur Internet qui perdure encore aujourd’hui. Certains artistes étaient d’accord avec la RIAA pour interdire le téléchargement de fichiers MP3, tandis que d’autres (dont beaucoup avaient subi des préjudices financiers de la part de leurs propres maisons de disques) accueillaient favorablement l’avènement de la distribution numérique. Napster a perdu son procès contre la RIAA et a fermé ses portes en 2002. Cela n’a pas empêché le partage de fichiers, mais les outils de remplacement comme eDonkey 2000, Limewire, Kazaa et Bearshare se trouvaient dans une zone grise juridique.
Finalement, c’est Apple qui a trouvé un terrain d’entente avantageux pour les deux parties. En 2003, deux ans après le lancement de son lecteur iPod, Apple a annoncé l’ouverture de l’iTunes Store, exclusivement en ligne. Steve Jobs avait signé des accords avec les cinq grandes maisons de disques pour permettre l’achat légal de chansons individuelles – étonnamment, sans protection contre la copie – pour 0,99 $ l’unité, ou d’albums complets pour 10 $. En 2010, l’iTunes Store était le plus grand vendeur de musique au monde.
iTunes 4.1, sorti en 2003. Il s’agissait de la première version pour Windows et elle a présenté l’iTunes Store à un monde plus largeLe Web devient 2.0
La vision originale de Tim Berners-Lee pour le Web consistait simplement à diffuser et à afficher des informations. C’était comme une bibliothèque, mais avec des liens hypertextes. Mais il n’a pas fallu longtemps pour que l’information circule dans l’autre sens. En 1994, Netscape 0.9 a ajouté de nouvelles balises HTML comme FORM et INPUT, permettant aux utilisateurs de saisir du texte et, grâce au bouton « Envoyer », de le renvoyer au serveur web.
Les premiers serveurs web ne savaient pas quoi faire de ce texte. Mais les programmeurs ont développé des extensions permettant à un serveur d’exécuter des programmes en arrière-plan. L’interface CGI (Common Gateway Interface) standardisée permettait à un bouton « Soumettre » de déclencher un programme (généralement situé dans un répertoire /cgi-bin/) capable d’effectuer une action intéressante avec la soumission, comme communiquer avec une base de données. Les scripts CGI pouvaient même générer dynamiquement de nouvelles pages web et les renvoyer à l’utilisateur.
Cette interaction bidirectionnelle intelligente a révolutionné le Web. Elle a permis des fonctionnalités telles que la connexion à un compte sur un site web, les forums en ligne et même le téléchargement de fichiers directement sur un serveur web. Soudain, un site web n’était plus une simple page que l’on consultait. Il pouvait devenir une communauté où des groupes de personnes intéressées pouvaient interagir et partager textes et images.
La première page de Geocities telle qu’elle aurait pu apparaître fin 1996. Geocities permet à chacun de créer sa propre maison sur le WebLes pages web dynamiques ont favorisé l’essor des blogs, d’abord à titre expérimental (certains, comme ceux de Justin Hall et de Dave Winer , existent encore aujourd’hui), puis comme activité accessible à tous pendant son temps libre. La création de sites web est devenue plus facile grâce à des plateformes comme Geocities et Angelfire, qui permettaient de construire gratuitement la maison de ses rêves en ligne. Un site communautaire de liens dynamiques, webring.org , connectait des sites web similaires, encourageant ainsi l’exploration.
Webring.org était un service gratuit géré par la communauté qui permettait de mettre à jour dynamiquement les anneaux WebWikipédia est l’un des meilleurs résultats du Web 2.0. Il est né d’un projet annexe de Nupedia , une encyclopédie en ligne fondée par Jimmy Wales, dont les articles étaient rédigés par des bénévoles experts en la matière. Ce processus était lent, et le site ne comptait que 21 articles la première année. Wikipédia, en revanche, permettait à chacun de contribuer et de réviser les articles, ce qui lui a rapidement permis de dépasser son prédécesseur. Au début, l’idée de laisser des internautes modifier des articles au hasard suscitait des réticences. Mais grâce à une armée de contributeurs bénévoles et à un ensemble d’outils permettant de corriger rapidement les actes de vandalisme, le site a prospéré. Wikipédia a largement dépassé des ouvrages comme l’Encyclopédie Britannica en termes de nombre d’articles, tout en conservant une précision à peu près équivalente .
Toutes les innovations Internet ne se résumaient pas à une page web. En 1988, Jarkko Oikarinen créa un programme appelé Internet Relay Chat (IRC), qui permettait la messagerie en temps réel entre individus et groupes. Les clients IRC pour Windows et Macintosh étaient populaires auprès des passionnés, mais des applications plus conviviales comme PowWow (1994), ICQ (1996) et AIM (1997) démocratisèrent la messagerie. Même Microsoft s’y est mis avec MSN Messenger en 1999. Pendant quelques années, cette culture de la messagerie a fait partie intégrante du quotidien, à la maison, à l’école et au travail.
Une reconstitution numérique de MSN Messenger de 2001. Malheureusement, Microsoft a fermé les serveurs en 2014Animation, jeux et vidéo
Alors que le Web évoluait rapidement, la lenteur des modems commutés limitait la taille des fichiers pouvant être téléchargés sur un site web. Les images statiques étaient la norme. Les animations n’apparaissaient que dans des fichiers GIF fortement compressés, contenant quelques images chacun.
Mais une nouvelle technologie a surmonté ces limites et a libéré un flot de créativité sur le Web. En 1995, Macromedia a lancé Shockwave Player, une extension pour Netscape Navigator. Associée à son logiciel Director, cette combinaison permettait aux artistes de créer des animations à partir de dessins vectoriels, suffisamment petites pour être intégrées à des pages web.
Des sites web ont vu le jour pour promouvoir ce nouveau contenu. Newgrounds.com, lancé en 1995 comme site de fans de Neo-Geo, a commencé à rassembler les meilleures animations. Conçu pour créer du multimédia interactif pour les projets sur CD-ROM, Director prenait également en charge les commandes au clavier et à la souris, ainsi que des scripts de base. Cela permettait de créer des jeux simples fonctionnant sous Shockwave. Newgrounds les a également présentés avec enthousiasme, offrant à de nombreux artistes et concepteurs de jeux en herbe un point de départ pour leur carrière. Super Meat Boy , par exemple, a été initialement prototypé sur Newgrounds.
Newgrounds tel qu’il aurait pu apparaître vers 2003Mettre de la vidéo sur le web semblait relever d’un futur lointain. Mais l’avenir est arrivé rapidement. Après le krach des dotcoms de 2001, de nombreux programmeurs web se sont retrouvés au chômage, disposant de beaucoup de temps libre pour expérimenter leurs projets personnels. L’arrivée du haut débit avec les modems câble et les lignes d’abonné numérique (DSL), combinée à la nouvelle norme de compression MPEG4, a rendu possibles de nombreuses choses auparavant impossibles.
Début 2005, Chad Hurley, Steve Chen et Jawed Karim ont lancé YouTube.com. Initialement conçu comme un site de rencontres en ligne, ce service a échoué. Le site, cependant, disposait d’une excellente technologie pour le téléchargement et la lecture de vidéos. Il utilisait Flash de Macromedia, une nouvelle technologie si similaire à Shockwave que l’entreprise l’a commercialisée sous le nom de Shockwave Flash. YouTube permettait à chacun de télécharger gratuitement des vidéos d’une durée maximale de dix minutes. Son succès a été tel que Google l’a racheté un an plus tard pour 1,65 milliard de dollars.
Toutes ces technologies se sont combinées pour offrir au grand public l’opportunité, même brève, d’influencer la culture populaire. Le phénomène All Your Base en est un exemple précoce. Un GIF animé d’un jeu Sega Genesis obscur et mal traduit a inspiré les musiciens indépendants The Laziest Men On Mars à créer une chanson et à la diffuser au format MP3. Le site humoristique populaire somethingawful.com l’a reprise, et les utilisateurs du forum Photoshop Friday ont créé une série d’images humoristiques pour accompagner la chanson. Puis, en 2001, l’utilisateur Bad_CRC a rassemblé la chanson et les meilleures images dans une animation partagée sur Newgrounds. La version YouTube a connu un tel succès qu’elle a été relayée par USA Today.
Vous n’avez aucune chance de survivre, prenez votre tempsLes médias deviennent sociaux (la France était encore scotchée au minitel)
Au début des années 2000, la plupart des sites web étaient soit des blogs, soit des forums, et souvent les deux. Ces forums proposaient de multiples forums de discussion, généraux et spécifiques. Ils étaient souvent axés sur un passe-temps ou un centre d’intérêt spécifique, et toute personne partageant ce centre d’intérêt pouvait s’y inscrire. Il existait également quelques sites de rencontres, comme kiss.com (1994), match.com (1995) et eHarmony.com (2000), qui cherchaient spécifiquement à mettre en relation des personnes susceptibles de s’intéresser l’une à l’autre.
Swedish Lunarstorm a été l’un des premiers sites de médias sociauxLe chemin vers les réseaux sociaux a été une fusion confuse et confuse de ces deux types de sites web. Il y a eu classmates.com (1995), qui permettait de retrouver d’anciens camarades de classe, et l’année suivante, le site suédois lunarstorm.com a été lancé avec cette mission :
Chacun a son propre site web appelé Krypin. Chaque bébé [ce mot est une traduction exacte] a son propre Krypin où il ou elle se présente, publie son journal intime et ses fichiers préférés, qui peuvent être des photos, des chansons, des poèmes et autres choses amusantes. Chaque LunarStormer a aussi son propre livre d’or où vous pouvez écrire si vous n’osez pas envoyer un LunarEmail ou une demande d’amitié.
En 1997, sixdegrees.com a été lancé, partant du principe que chaque être humain est connecté à six degrés de séparation ou moins. Sa page « À propos » indiquait : « Nos services de réseautage gratuits vous permettent de trouver les personnes que vous souhaitez rencontrer grâce à vos connaissances actuelles. »
À l’ ouverture de friendster.com en 2002, le concept de « rejoindre quelqu’un » en ligne était déjà bien établi, même s’il s’agissait encore d’une activité de niche. LinkedIn.com, lancé l’année suivante, a utilisé le prétexte du réseautage professionnel pour encourager ce comportement. Mais c’est MySpace.com (2003) qui a été le premier à connaître un succès significatif.
MySpace était à l’origine un clone de Friendster, développé en seulement dix jours par les employés d’eUniverse, une start-up de marketing en ligne fondée par Brad Greenspan. Il est devenu le produit le plus populaire de l’entreprise. MySpace combinait les capacités de création de sites web de sites comme GeoCities avec les fonctionnalités des réseaux sociaux. Son essor a été fulgurant : en seulement trois ans, il a dépassé Google comme site web le plus visité aux États-Unis. L’engouement pour MySpace a atteint un tel pic que Rupert Murdoch l’a racheté en 2005 pour 580 millions de dollars.
Mais un nouveau venu sur la scène des médias sociaux était sur le point de détruire MySpace. Tout comme Google a écrasé ses concurrents, cette startup a gagné en proposant un produit plus simple, plus fonctionnel et moins intrusif. TheFaceBook.com a vu le jour grâce à la tentative de Mark Zuckerberg et de son colocataire de remplacer l’annuaire en ligne de leur université. Le premier site web étudiant de Zuckerberg, « Facemash », avait été créé en s’introduisant dans le réseau de Harvard et sa seule fonctionnalité était de proposer des comparaisons de photos d’étudiants « Hot or Not ». Facebook s’est rapidement étendu à d’autres universités et, en 2006 (après la suppression du « the »), il a été ouvert au reste du monde.
« Le » Facebook tel qu’il apparaissait en 2004Facebook a remporté la bataille des réseaux sociaux en misant sur la rapidité de déploiement de nouvelles fonctionnalités. Le slogan de l’entreprise, « Move fast and disrupt things », a encouragé cette stratégie. La fonctionnalité la plus marquante, ajoutée en 2006, était le fil d’actualité. Il générait une liste de publications, sélectionnées parmi des milliers de mises à jour potentielles pour chaque utilisateur en fonction de ses abonnés et de ses préférences, et l’affichait sur sa page d’accueil. Associé à une technique appelée « défilement infini », inventée par Hugh E. Williams pour la recherche d’images Bing de Microsoft en 2005, il a révolutionné le fonctionnement du web.
Le fil d’actualité généré par algorithme a créé de nouvelles opportunités de profit pour Facebook. Par exemple, les entreprises pouvaient booster leurs publications moyennant finance, ce qui les faisait apparaître plus souvent dans les fils d’actualité. Cela brouillait la frontière entre publications et publicités.
Facebook a également réussi à identifier les réseaux sociaux émergents et à les racheter avant qu’ils ne représentent une menace. Cette opération a été facilitée par Onavo , un VPN qui surveillait les activités de ses utilisateurs et revendait les données. Facebook a racheté Onavo en 2013. L’entreprise a été fermée en 2019 en raison de la controverse persistante sur l’utilisation des données privées.
Les médias sociaux ont transformé Internet, attirant des millions de nouveaux utilisateurs et initiant une consolidation des habitudes de visite des sites web qui perdure encore aujourd’hui. Mais un autre événement allait se produire, qui allait bouleverser Internet en profondeur.
Vous n’avez pas de téléphone ?
Pendant des années, les utilisateurs expérimentés ont expérimenté l’accès à Internet sur leurs appareils portables. Le téléphone Simon d’IBM , sorti en 1994, possédait à la fois des fonctionnalités de téléphone et de PDA. Il permettait d’envoyer et de recevoir des e-mails. Le Nokia 9000 Communicator , sorti en 1996, disposait même d’un navigateur web textuel primitif.
Les téléphones ultérieurs, comme le Blackberry 850 (1999), le Nokia 9210 (2001) et le Palm Treo (2002), ont été dotés de claviers, d’écrans couleur et de processeurs plus rapides. En 1999, le protocole WAP (Wireless Application Protocol ) a été lancé, permettant aux téléphones mobiles de recevoir et d’afficher des pages simplifiées et optimisées pour les téléphones grâce au langage WML, au lieu du langage HTML standard.
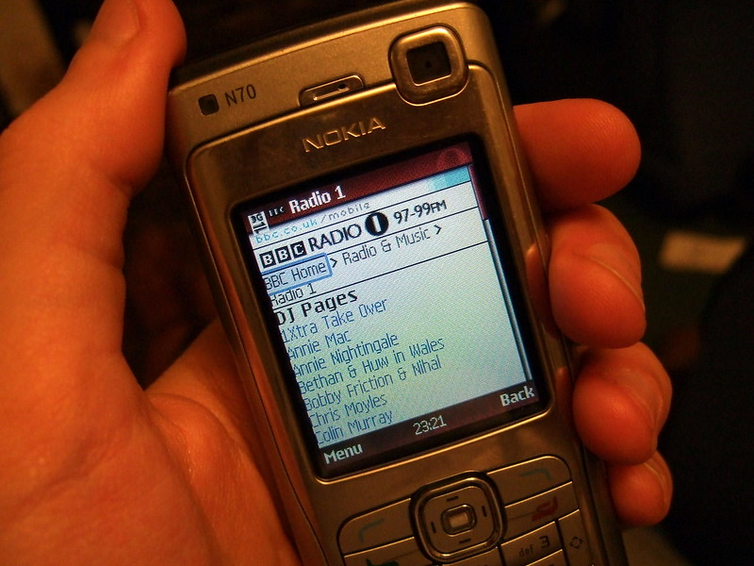
Naviguer sur le Web sur les téléphones était possible avant les smartphones modernes, mais ce n’était pas facileMalgré leur popularité auprès des professionnels, ces téléphones n’ont jamais conquis le grand public. Tout a changé en 2007, lorsque Steve Jobs est monté sur scène et a annoncé l’iPhone. Désormais, toutes les pages web pouvaient être consultées nativement sur le navigateur du téléphone, et zoomer sur une section était aussi simple qu’un pincement ou un double-clic. Flash faisait exception , mais une nouvelle norme HTML 5 promettait de standardiser les fonctionnalités web avancées comme l’animation et la lecture vidéo.
Google a rapidement transformé son prototype Android, passant d’un clone de BlackBerry à un système plus proche de l’iPhone. La structure de licence ouverte d’Android a permis aux entreprises du monde entier de produire des smartphones à bas prix. Même les téléphones milieu de gamme restaient bien moins chers que les ordinateurs. Cette technologie a permis, pour la première fois, au monde entier d’être connecté à Internet.
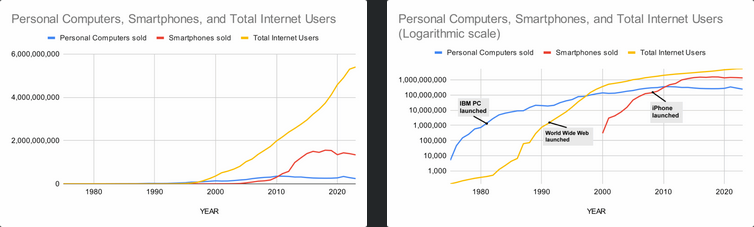
Graphique des ventes d’ordinateurs personnels et de smartphones chaque année, ainsi que du nombre total d’utilisateurs d’Internet. L’échelle logarithmique nous permet de voir les événements clés de l’histoire de la technologieL’explosion du nombre d’utilisateurs de téléphones a également propulsé la croissance massive des réseaux sociaux comme Facebook et Twitter. Il était désormais bien plus facile de prendre une photo d’un événement en direct avec son téléphone et de la partager instantanément avec le monde entier. Les optimistes ont cité les événements marquants du Printemps arabe comme preuve qu’Internet pouvait contribuer à la diffusion de la démocratie et de la liberté. Mais les gouvernements du monde entier étaient tout aussi désireux d’utiliser ces nouveaux outils, mais leurs objectifs étaient davantage axés sur le contrôle et la répression de la dissidence.
Le contrecoup
La technologie a toujours été une arme à double tranchant. Mais ces dernières années, l’opinion publique à l’égard d’Internet est passée d’une opinion majoritairement positive à une opinion de plus en plus négative.
La combinaison des téléphones portables, des algorithmes des réseaux sociaux et du défilement infini a donné naissance au phénomène du « doomscrolling », où l’on passe des heures chaque jour à lire des « informations » conçues pour susciter un engagement maximal en provoquant le plus grand nombre. Il a été démontré que le stress émotionnel causé par le doomscrolling est réellement préjudiciable . Plus graves encore sont les conséquences de la désinformation et des discours de haine, comme le génocide au Myanmar, qui, selon un rapport d’Amnesty International, a été amplifié sur Facebook .
À mesure que des entreprises comme Google, Amazon et Facebook se sont transformées en quasi-monopoles, elles ont inévitablement perdu de vue leur mission première au profit d’une quête incessante de profits. Ce processus, baptisé « enshittification » par Cory Doctorow, déplace l’attention des utilisateurs vers les annonceurs, puis vers les actionnaires.
La course aux profits a alimenté l’essor de l’IA générative, qui menace de transformer Internet en une mer de boue grise et sans âme. Google impose désormais des résumés d’IA en tête des recherches web, ce qui réduit le trafic vers les sites web et fournit souvent de dangereuses informations erronées . Mais même en ignorant ces résumés, les sites que vous trouvez en dessous peuvent également être suspects. Des sites web autrefois fiables ont licencié du personnel et l’ont remplacé par l’IA , générant une série interminable de nouveaux articles rédigés par personne. Un web où les IA commentent des publications Facebook générées par l’IA et renvoient vers des articles générés par l’IA, lesquels sont ensuite résumés par l’IA par Google, semble inhumain et inutile.
Recherche de bébés paons mignons sur Bing. Certains sont réels, d’autres nonQuel chemin a-t-on parcouru ?
L’histoire d’Internet peut être divisée en trois phases. La première, de 1969 à 1990, était celle des inventeurs : des personnes comme Vint Cerf, Steve Crocker et Robert Taylor. Ces personnes faisaient partie d’un petit groupe d’informaticiens qui ont découvert comment faire communiquer différents types d’ordinateurs entre eux et avec d’autres réseaux.
La phase suivante, de 1991 à 1999, fut une véritable révolution alimentée par des entrepreneurs comme Jerry Yang et Jeff Bezos. Ils s’emparèrent de l’invention du World Wide Web par Tim Berners-Lee et créèrent des entreprises entièrement intégrées à ce nouveau paysage numérique. Cela déclencha une phase frénétique de croissance exponentielle et d’engouement, qui culmina début 2001 et s’effondra quelques mois plus tard.
La phase finale, de 2000 à aujourd’hui, a principalement concerné les utilisateurs. De nouvelles entreprises comme Google et Facebook ont peut-être récolté les plus gros bénéfices financiers durant cette période, mais aucun de leurs succès n’aurait été possible sans la contribution de personnes ordinaires comme vous et moi. Chaque fois que nous saisissions quelque chose dans une zone de texte et que nous cliquions sur le bouton « Envoyer », nous créions un minuscule fragment d’un gigantesque réseau de contenu. Même les IA génératives qui prétendent créer de nouvelles choses aujourd’hui ne font que régurgiter des mots, des phrases et des images créés et partagés par des personnes.
On ressent aujourd’hui une nostalgie croissante pour l’ ancien Internet , une époque où l’on se sentait comme un lieu, et où la joie de la découverte était omniprésente. « Utiliser l’ancien Internet, c’était comme chercher un trésor », a déclaré le commentateur YouTube MySoftCrow. « Utiliser l’Internet actuel, c’est comme être enterré vivant. »
MichaelHurd, membre de la communauté Ars, a ajouté : « Je partage cet avis. J’ai l’impression que le problème principal de l’Internet moderne est que les sites web veulent que vous y restiez le plus longtemps possible, alors que le World Wide Web est à son meilleur lorsque les sites sont connectés les uns aux autres et encouragent les utilisateurs à naviguer entre eux. C’est à cela que servent les hyperliens ! »
Malgré le pessimisme qui entoure l’Internet moderne, celui-ci reste largement ouvert. N’importe qui peut payer environ 5 dollars par mois pour un serveur Linux partagé et créer un site web personnel contenant tout ce qui lui passe par la tête, avec n’importe quel logiciel, même le sien. Et, dans la plupart des cas, n’importe qui, sur n’importe quel appareil et partout dans le monde, peut accéder à ce site web.
En fin de compte, le sort d’Internet dépend des actions de chacun d’entre nous. C’est pourquoi je vous laisse le mot de la fin de cette série d’articles. À quoi ressemblerait l’Internet du futur selon vous ? La section commentaires est ouverte.
Source: https://arstechnica.com/gadgets/2025/09/a-history-of-the-internet-part-3-the-rise-of-the-user/
-
Reserve
-
Monsieur est prévoyant …!
-
et dire que j’ai travaillé avec ces bandes de telex
")
j’étais tellement jeune 19 ans à peine Nom de diou
-
Les partie 2 et 3 sont maintenant disponibles en haut du topic sous la partie 1, les anciens, préparez vos mouchoirs pour la séquence nostalgie
")